
Google Accelerates Gemma 4 by 3x with Multi-Token Prediction
Edition #290 | 08 May 2026

Google Accelerates Gemma 4 by 3x with Multi-Token Prediction Speculative Decoding
In this edition, we will also be covering:
Norway joins US-led effort to secure AI supply chains
OpenAI releases GPT-5.5 Instant, a new default model for ChatGPT
Anthropic and OpenAI are both launching joint ventures for enterprise AI services
Today’s Quick Wins
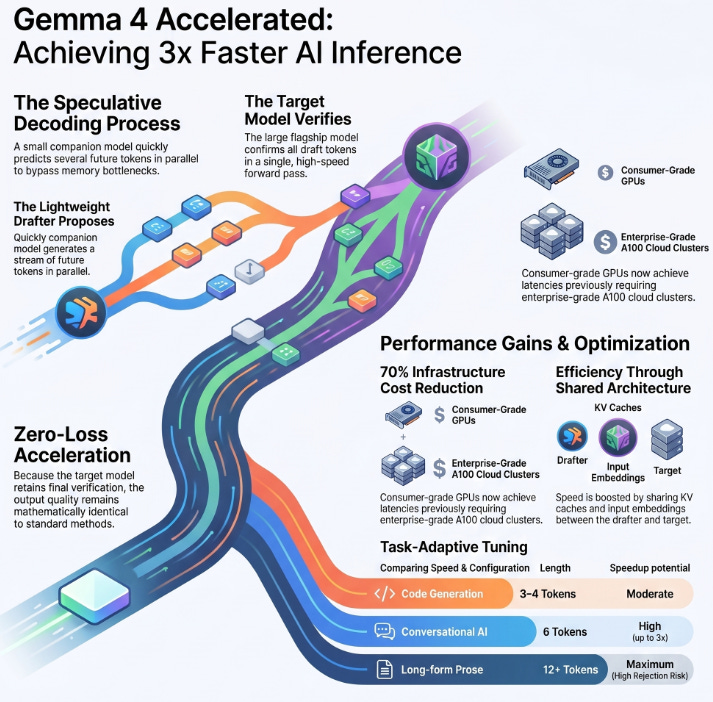
What happened: On May 5, Google released Multi-Token Prediction (MTP) drafter models for its entire Gemma 4 open-model family including the 31B dense flagship, the 26B Mixture-of-Experts variant, and on-device E2B/E4B edge models. Using speculative decoding, the drafters deliver up to 3x faster inference with zero degradation in output quality or reasoning accuracy, and the Gemma 4 family has already accumulated 60 million downloads since its April launch.
Why it matters: Inference latency is the silent killer of production ML deployments. A 3x wall-clock speedup on consumer GPUs and Apple Silicon means smaller teams can now run frontier-class open models locally without enterprise-grade hardware collapsing the cost differential between open and closed models.
The takeaway: If you’re deploying any Gemma 4 variant via vLLM, Hugging Face Transformers, MLX, or Ollama, MTP drafter support is available today with minimal configuration changes there’s no reason not to upgrade your inference pipeline this week.
Deep Dive
Why Google’s Gemma 4 MTP Drafters Are a Turning Point for Open-Model Inference
For the past two years, the dominant narrative in enterprise AI has been a trade-off: open models are cheaper to run, but closed API models are faster and more capable. Google just chipped away at the speed side of that equation and the mechanism it used is worth understanding in detail.
The Problem: Standard transformer inference is fundamentally memory-bandwidth bound. For every single token generated, the GPU must load billions of model parameters from VRAM into compute units and then sit mostly idle while that transfer completes. On a Gemma 4 31B model, this bottleneck produces painfully high latency, particularly at batch size 1 (i.e., a single user query). The compute hardware is underutilized; you’re paying for a sports car but spending most of the time at traffic lights.
The Solution: Google’s MTP drafters implement speculative decoding a technique that decouples token generation from token verification. Rather than relying on the large “target” model to produce every token sequentially, a lightweight companion drafter proposes several future tokens cheaply and in parallel. The heavy model then verifies them all in a single forward pass. If the draft tokens match what the target would have generated, you get multiple tokens for the latency cost of one. Crucially, because the target model retains the final verification step, the output is mathematically identical to standard autoregressive decoding it is a lossless speedup.
Three architectural choices make the Gemma 4 MTP drafters particularly efficient:
Shared input embeddings: The drafter reuses the target model’s full embedding table instead of learning a separate one, dramatically reducing parameter overhead and keeping the companion model small.
Target-activation conditioning: The drafter uses intermediate activations from the target model’s forward pass to condition its predictions, making proposals more accurate and increasing the token acceptance rate.
Shared KV cache: Both models share the same key-value cache for attention computation, so the drafter never recomputes context the target has already processed eliminating the most expensive redundant operation in speculative decoding.
The Results Speak for Themselves:
Baseline: Gemma 4 31B dense model, standard autoregressive decoding, ~1x tokens/second
After Optimization: Up to 3x tokens/second with MTP drafters across LiteRT-LM, MLX, vLLM, and Hugging Face Transformers backends
Business Impact: Consumer-grade hardware (single NVIDIA RTX-class GPU or Apple M-series) can now serve Gemma 4 31B at latencies previously requiring A100-class cloud inference estimated 60–70% infrastructure cost reduction for teams running on-prem workloads
What We’re Testing This Week
Speculative Decoding in Practice: Tuning Draft Length for Your Workload
Not all tasks benefit equally from speculative decoding. The acceptance rate the fraction of drafted tokens the target model actually confirms varies significantly by task type. Higher acceptance rates mean larger effective speedups; lower rates mean wasted compute on rejected drafts. Here’s how to configure draft length intelligently for your use case.
1. Task-adaptive draft length selection. Google’s own benchmarks show that conversational and summarization tasks achieve acceptance rates high enough to support 5–8 draft tokens, yielding the full 3x gain. Code generation tasks, where the next token is far less predictable (variable names, bracket choices, indentation), perform best at 3–4 draft tokens before acceptance rates drop and the speedup stalls. Long-form prose generation can push 10–15 draft tokens but requires monitoring rejection rates closely to avoid burning compute on speculative paths the target discards.
python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load the target model (e.g., Gemma 4 31B) and its MTP drafter
model_name = "google/gemma-4-31b-it"
drafter_name = "google/gemma-4-31b-it-mtp" # companion drafter checkpoint
tokenizer = AutoTokenizer.from_pretrained(model_name)
target_model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
drafter_model = AutoModelForCausalLM.from_pretrained(
drafter_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# Task-aware draft token tuning
TASK_DRAFT_LENGTHS = {
"conversational": 6, # High acceptance rate
"summarization": 7, # Predictable token sequences
"code_generation": 3, # Lower predictability
"long_form_prose": 12, # Monitor rejection rate
}
def generate_with_speculative_decoding(prompt: str, task: str = "conversational") -> str:
num_draft_tokens = TASK_DRAFT_LENGTHS.get(task, 5) # default: 5
inputs = tokenizer(prompt, return_tensors="pt").to(target_model.device)
# Pass the drafter as the assistant model — HF Transformers handles the rest
output = target_model.generate(
**inputs,
assistant_model=drafter_model,
num_assistant_tokens=num_draft_tokens,
max_new_tokens=512,
do_sample=False, # Greedy decoding maximizes acceptance rate
)
return tokenizer.decode(output[0], skip_special_tokens=True)
# Example: Summarization task (higher draft length = bigger speedup)
result = generate_with_speculative_decoding(
prompt="Summarize the key trends in enterprise AI adoption for 2026:",
task="summarization"
)
print(result)2. Monitoring acceptance rate at runtime. If you’re using vLLM or SGLang in production, both frameworks expose speculative decoding acceptance-rate metrics via their Prometheus endpoints. Track speculative_decoding_acceptance_rate as a p50/p95 metric if it dips below 0.5 consistently, reduce your draft length by 2 tokens. If it stays above 0.85, try increasing it to capture more latency gains.
Recommended Tools
This Week’s Game-Changers
Gemma 4 MTP Drafters (Google) Open-weight speculative decoding companions for Gemma 4 31B, 26B MoE, E2B, and E4B delivering up to 3x inference speedup with zero quality loss under Apache 2.0. Check it out
vLLM 0.9+ The leading open-source LLM inference engine with first-class speculative decoding support plug in any Gemma 4 MTP drafter as
speculative_modeland get hardware-optimized paged attention out of the box. Check it outWorkday Data Cloud (Workday) New this week: governed real-time SQL access to live Workday HR and finance data, with direct connectors to Databricks and Snowflake for analytics pipelines no ETL required. Check it out
Quick Poll
Lightning Round
3 Things to Know Before Signing Off
Norway joins US-led effort to secure AI supply chains
Norway is joining the U.S.-led Pax Silica initiative to ensure reliable AI supply chains and reduce China dependence. The Nordic country will sign on Wednesday, boosting Norwegian firms’ access to advanced tech value chains, per Trade Minister Cecilie Myrseth.
OpenAI releases GPT-5.5 Instant, a new default model for ChatGPT
OpenAI launched GPT-5.5 Instant, replacing GPT-5.3 as ChatGPT’s default, with reduced hallucinations in law, medicine, finance, better math scores (81.2 on AIME 2025), and enhanced context via search tools. Developers access it as “chat-latest.”
Anthropic and OpenAI are both launching joint ventures for enterprise AI services
Anthropic partners with Blackstone, Hellman & Friedman, Goldman Sachs for a $1.5B venture deploying enterprise AI, using forward-deployed engineers. OpenAI’s $10B Development Company raises $4B from TPG, Brookfield for similar scaled services.
Follow Us:
LinkedIn | X (formerly Twitter) | Facebook | Instagram
Please like this edition and put up your thoughts in the comments.