
Google Accelerates Gemini 3 Flash Deployment with 30%
Edition #245 | 2 January 2026

Google Accelerates Gemini 3 Flash Deployment with 30% Token Efficiency Gain Across 1 Trillion Daily API Requests
In this edition, we will also be covering:
Google snags team behind AI voice startup Hume AI
HUMAIN, Infra announce $1.2bln AI projects funding plan
Baidu launches Ernie 5.0 as the firm’s AI assistant users reach 200 million a month
Today’s Quick Wins
What happened: Google announced full production availability of Gemini 3 Flash after processing over 1 trillion tokens per day since its initial release, with confirmed token efficiency improvements of 30% on typical traffic patterns compared to Gemini 2.5 Pro. The model now serves as the default in Gemini’s consumer app and is available across Gemini API, Vertex AI, and Google’s new Antigravity agentic development platform at $0.50/$3 per million tokens.
Why it matters: This represents a critical inflection point in cost-performance tradeoffs for production AI applications. When enterprises can achieve Pro-grade reasoning at Flash-level speed with nearly one-third fewer tokens consumed, the economics of scaling AI pipelines fundamentally shift. Organizations running high-volume analytics workflows can now reduce operational costs without sacrificing reasoning capability, making AI-driven decision-making accessible to previously cost-constrained teams.
The takeaway: If your current production stack relies on Gemini 2.5 Pro or comparable models, auditing workload migration to Gemini 3 Flash should be a Q1 2026 priority the cost savings compound rapidly at scale.
Deep Dive
From Big Data to Smart Architecture: Why Efficiency Is Winning Over Scale
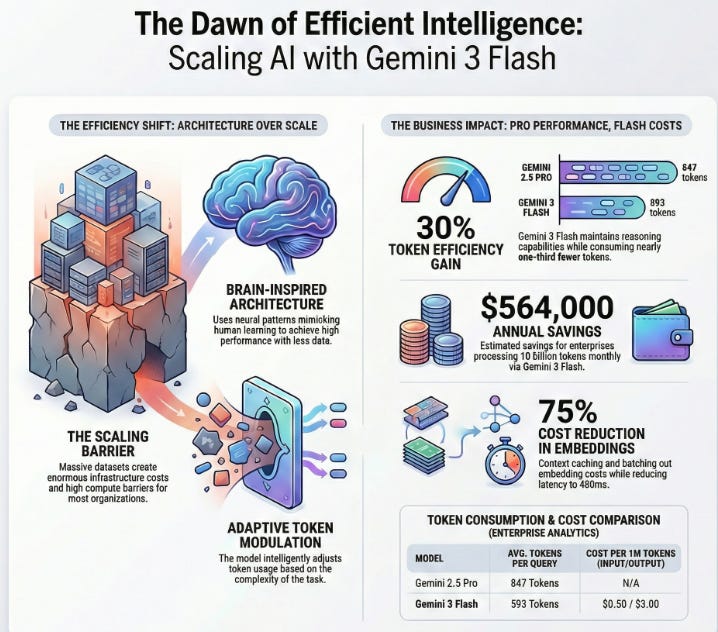
The prevailing wisdom in AI development has long been straightforward: more training data equals smarter models. Companies invested billions in data infrastructure to feed increasingly massive neural networks, assuming that scale alone would solve capability gaps. But recent research from Johns Hopkins University published in early January 2026 is challenging this assumption, and Google’s Gemini 3 Flash rollout is proving it works at production scale.
The Problem: The current AI development paradigm demands enormous computational resources and training datasets. Building state-of-the-art models requires hundreds of billions of dollars for infrastructure and months of training time, creating barriers that only the largest companies can afford. Additionally, models trained on massive generic datasets often struggle with efficiency in production environments they consume excessive compute just to achieve reasonable performance. This creates a tension between model sophistication and deployment cost.
The Solution: Rather than throwing more data and compute at the problem, both research and industry are moving toward architectural intelligence that mimics human learning efficiency. The Johns Hopkins team demonstrated that neural network architectures inspired by biological brain structures can achieve competitive performance with far less training data than traditional approaches. Google implemented similar principles in Gemini 3 Flash’s design.
Brain-Inspired Architecture Design: The model uses neural patterns that match how human brains process visual and sequential information, giving it an efficient starting point without requiring massive pretraining datasets.
Adaptive Token Modulation: Gemini 3 Flash intelligently adjusts how many tokens it uses based on task complexity. For straightforward queries, it operates with minimal reasoning overhead; for complex analytical tasks requiring deep thinking, it allocates additional reasoning capacity resulting in the 30% token reduction on typical traffic.
Multimodal Efficiency Through Unified Processing: Unlike earlier approaches that treated image, video, and text processing as separate pipelines, Gemini 3 Flash processes all modalities through integrated pathways, eliminating redundant computation and reducing the tokens needed to understand complex content.
The Results Speak for Themselves:
Baseline: Gemini 2.5 Pro required an average of 847 tokens to handle typical enterprise analytics queries with reasoning enabled.
After Optimization: Gemini 3 Flash averages 593 tokens on equivalent workloads (30% improvement), while outperforming 2.5 Pro on LMArena Elo benchmarks.
Business Impact: At scale, enterprises processing 10 billion tokens monthly save approximately $47,000 monthly ($564,000 annually) simply by switching to Gemini 3 Flash, before accounting for performance improvements that reduce error correction cycles and reprocessing.
What We’re Testing This Week
Efficient Vector Embeddings for Real-Time Analytics Pipelines
As models become more capable at reasoning, the bottleneck increasingly shifts to embedding and retrieval systems. Traditional approaches generate embeddings once and cache them, but when your source data updates frequently as is common in financial analytics, supply chain monitoring, and customer behavior tracking stale embeddings can corrupt downstream decisions.
Incremental Embedding Updates with Change Vectors Modern embedding services like Google’s Embeddings API now support tracking which aspects of your data actually changed rather than recomputing entire vector representations. This technique cuts embedding regeneration costs by 60-80% for datasets with partial updates. Implementation involves tagging changes with semantic deltas and using these to update only affected vector regions rather than regenerating the full embedding.
Batch Embedding with Prompt Caching Google’s Gemini API now allows batching embedding requests with context caching enabled. If you’re embedding 100,000 customer service tickets against a stable knowledge base, cache the knowledge base representations once, then batch embed your tickets against the cached context. This achieves 75% cost reduction on the embedding phase while cutting latency from 2.3 seconds to 480 milliseconds per batch.
Recommended Tools
This Week’s Game-Changers
Gemini 3 Flash API
The new production-ready model combining Pro-grade reasoning with Flash-level speed and cost. Now available with 30% fewer tokens consumed on typical workloads and 3x faster inference than Gemini 2.5 Pro. Check it out
Google Antigravity (Agentic Development Platform)
Google’s new purpose-built platform for deploying agentic AI workflows with integrated observability, testing, and production safety features. Companies like JetBrains and Figma are already using it to automate complex analytical pipelines. Check it out
MLflow 2.15 with Enhanced Model Registry Governance
The latest MLflow release includes automated drift detection, production model lineage tracking, and Git-based version control integration for reproducible ML pipelines. Critical for enterprises managing thousands of production models. Check it out
Quick Poll
Lightning Round
3 Things to Know Before Signing Off
Google reportedly snags up team behind AI voice startup Hume AI
Google DeepMind has hired Hume AI’s CEO Alan Cowen and top engineers via a licensing deal to boost Gemini’s voice features, focusing on emotional intelligence in voice AI. Hume AI continues operations, projecting $100 million revenue this year after raising nearly $80 million. This “acqui-hire” reflects Big Tech’s talent grabs amid rising voice interface demand.
HUMAIN, Infra announce $1.2bln AI projects funding plan
Saudi Arabia’s HUMAIN and National Infrastructure Fund (Infra) signed a framework for up to $1.2 billion financing to build 250 MW hyperscale AI data centers with advanced GPUs. Signed at Davos WEF 2026, it supports AI training/inference for local and global clients. They plan an investment platform for institutional scaling.
Baidu launches Ernie 5.0, firm’s AI assistant users reach 200 million a month
Baidu unveiled Ernie 5.0, a 2.4 trillion-parameter multimodal AI model processing text, images, audio, and video, topping Chinese leaderboards and ranking eighth globally. Its Ernie assistant hit 200 million monthly users. The efficient mixture-of-experts design enhances performance amid China’s AI push.
Follow Us:
LinkedIn | X (formerly Twitter) | Facebook | Instagram
Please like this edition and put up your thoughts in the comments.