
FREE: Google DeepMind Ships Diffusion Gemma 26B
Edition #311 | 15 June 2026

Google DeepMind Ships Diffusion Gemma 26B, Achieves 4x Faster Token Generation with Parallel Text Diffusion
In this edition, we will also be covering:
Oracle to spend $70bn on data centre build-out in coming year
Anthropic disables access to Fable 5 and Mythos 5 to comply with government directive
Huawei is considering deploying Ascend AI chips in Latin America, cloud chief says
Today’s Quick Wins
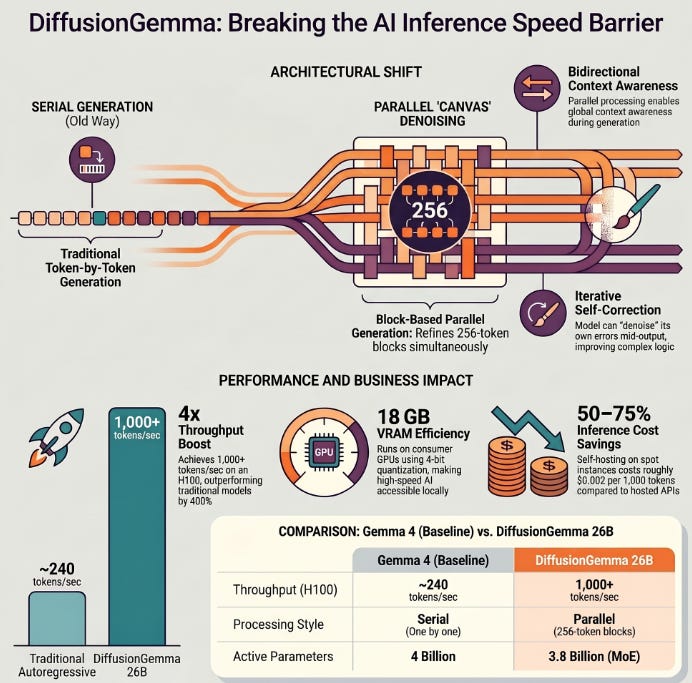
What happened: Google DeepMind released DiffusionGemma on June 10, 2026 a 26B Mixture-of-Experts open model that scraps token-by-token autoregressive decoding entirely. Instead, it refines 256-token blocks in parallel using Uniform State Diffusion, hitting 1,000+ tokens/sec on a single H100 and 700+ tokens/sec on an RTX 5090, roughly 4x faster than the comparable Gemma 4 26B-A4B at matched benchmark quality.
Why it matters: Inference speed has been the stubborn bottleneck for interactive AI applications agents, chat assistants, and real-time pipelines. A production-ready, Apache 2.0-licensed model that runs in 18 GB VRAM and ships with native vLLM support fundamentally lowers the cost curve for any team running local or cloud inference at scale.
The takeaway: If you’re paying per-token on hosted APIs for high-throughput workloads, DiffusionGemma’s self-hosted path on modest GPU hardware could cut inference costs by 50–75% worth a benchmark against your current stack this week.
Deep Dive
Why DiffusionGemma Changes How You Should Think About Inference Architecture
For three years, the implicit assumption in LLM deployment has been simple: faster hardware, same autoregressive algorithm. DiffusionGemma challenges that at the architecture level, and the implications for data and ML teams are practical and immediate.
The Problem: Autoregressive models are serially bottlenecked by design. Every token depends on the previous one, meaning generation latency scales linearly with output length. For an agent loop generating 512-token tool-call responses, you’re waiting in line no matter how many GPUs you throw at it.
The Solution: DiffusionGemma uses a masked diffusion approach it initializes the entire output canvas with noise tokens and iteratively denoises all positions in parallel, similar to how image diffusion models refine a full frame rather than painting pixel-by-pixel.
Architecture 26B MoE, 3.8B active: The Mixture-of-Experts design means only 3.8 billion parameters are active per forward pass, giving you the knowledge capacity of a 26B model at the compute cost closer to a 4B model. VRAM floor is 18 GB in NVFP4 quantization.
Parallel block generation: Rather than a single token stream, the model refines 256-token canvases simultaneously using bidirectional attention something autoregressive models structurally cannot do. This enables global context awareness during generation itself, not just in the prompt.
Self-correction via iterative denoising: Because generation is iterative, the model can self-correct mid-output. The fine-tuned Sudoku variant demonstrated this starkly: the base model solved ~0% of puzzles; the fine-tuned version reached 80% success purely by leveraging iterative constraint satisfaction during inference.
The Results Speak for Themselves:
Baseline: Gemma 4 26B-A4B (autoregressive, MTP-accelerated) on H100
After Optimization: DiffusionGemma 26B on same hardware - ~4x faster throughput at comparable benchmark scores
Business Impact: Self-hosted on a single H100 at $2–3/hr cloud spot pricing, 1,000+ tokens/sec throughput translates to roughly $0.002 per 1,000 output tokens - a fraction of comparable hosted API pricing for teams processing millions of tokens daily
Weights are live on Hugging Face at google/diffusiongemma-26B-A4B-it, and it deploys today via vLLM with an OpenAI-compatible endpoint.
What We’re Testing This Week
Running DiffusionGemma Locally with vLLM - Two Approaches Worth Benchmarking
DiffusionGemma is the first diffusion LLM with native vLLM support, which means you can swap it into an existing inference stack with minimal changes. Here’s what’s worth testing:
vLLM OpenAI-compatible serving (recommended for production) DiffusionGemma ships with day-zero vLLM support, continuous batching, and standard
/v1/completionsendpoints. In early benchmarks, vLLM serving on H100 sustains 900–1,000+ tokens/sec under concurrent load, versus ~240 tokens/sec for a comparable autoregressive model. Drop-in replacement for any OpenAI SDK client just pointbase_urlat your vLLM server.
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="not-needed-for-local"
)
response = client.completions.create(
model="google/diffusiongemma-26B-A4B-it",
prompt="Analyze the following dataset summary and identify anomalies:\n\n",
max_tokens=512,
temperature=0.7
)
print(response.choices[0].text)HuggingFace Transformers + NVFP4 quantization (best for dev/testing) -If you don’t have a vLLM server handy, load directly via Transformers with 4-bit quantization. Runs inside 18 GB VRAM on a single consumer GPU. Practical tip:
torch_dtype=torch.float16will OOM on a 24 GB card at full precision always load withload_in_4bit=Trueuntil llama.cpp GGUF support lands (expected later this month).
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "google/diffusiongemma-26B-A4B-it"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True, # Required: keeps VRAM under 18 GB
device_map="auto",
torch_dtype=torch.bfloat16
)
inputs = tokenizer("Summarize key trends in this Q2 sales data:", return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=256)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Recommended Tools
This Week’s Game-Changers
DiffusionGemma 26B-A4B
Google DeepMind’s open-weight text diffusion model generating 256-token blocks in parallel 4x faster than autoregressive alternatives. Apache 2.0, runs in 18 GB VRAM. Check it outvLLM 0.9+
The fastest open-source LLM inference engine, now with native DiffusionGemma support and continuous batching for production deployments. Drops into your existing OpenAI-compatible stack. Check it outWorkday Data Cloud (SQL Access)
Workday’s new governed, real-time SQL access layer connects live HR and finance data directly to Databricks and Snowflake useful if you’re building analytics pipelines on workforce or payroll data. Check it out
Quick Poll
Lightning Round
3 Things to Know Before Signing Off
Oracle to spend $70bn on data centre build-out in coming year
Oracle plans to invest $70 billion next year for data centre expansion amid rising debt and flat revenue, potentially raising $40 billion through debt and equity financing.
Anthropic disables access to Fable 5 and Mythos 5 to comply with government directive
Anthropic blocked access to Fable 5 and Mythos 5 models per a U.S. export control directive citing national security, restricting all foreign nationals globally.
Huawei is considering deploying Ascend AI chips in Latin America ...
Huawei is studying deploying its newest Ascend AI chips in Latin American cloud services, pushing Chinese hardware deeper into a region dominated by U.S. suppliers.
Follow Us:
LinkedIn | X (formerly Twitter) | Facebook | Instagram
Please like this edition and put up your thoughts in the comments.