
Databricks Genie Powers Enterprise Data Mastery
Edition #302 | 05 June 2026

How Will You Drive Resilience in the Face of AI?

AI killed traditional cybersecurity. AI-powered attacks happen in 27 seconds. Recovery takes 27 days - or weeks. Join us at Forward to understand today’s threats and discover state of the art solutions for Agentic Cyber Resilience. Hear from celebrity John Cena and Jason Clinton, CISO at Anthropic.
Databricks Genie Hits 90% Accuracy on Enterprise Data Queries with Multi-LLM Parallel Reasoning
In this edition, we will also be covering:
Amazon unveils new AI warehouse robot in $12bln Europe push
Meta repeatedly pushes back new AI model release for developers
Megaport secures 4 AI deals, to raise $594 million to build inference cloud
Today’s Quick Wins
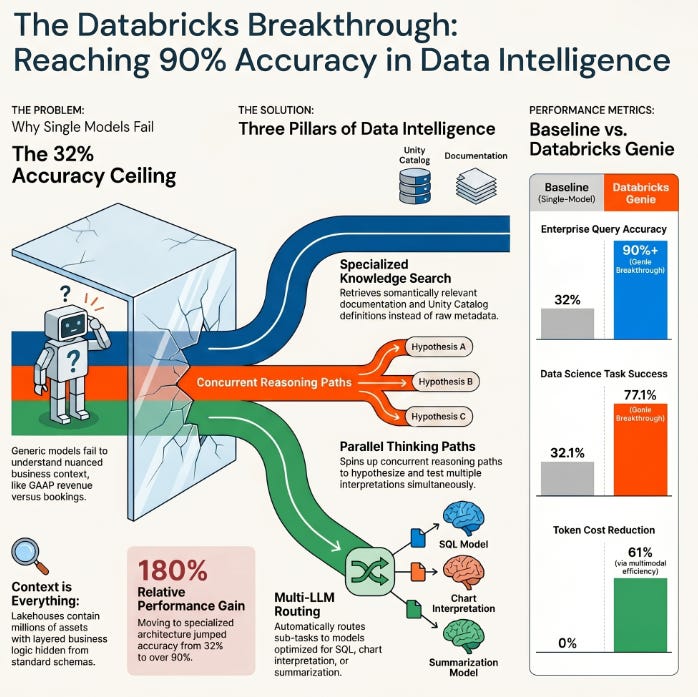
What happened: Databricks published research showing its Genie data agent jumped from 32% to over 90% accuracy on internal enterprise benchmarks by replacing single-model coding agents with a specialized architecture combining parallel thinking, knowledge search, and a multi-LLM pipeline. In parallel, Genie Code the agentic workflow layer on top more than doubled real-world data science task success rates from 32.1% to 77.1%.
Why it matters: Most enterprise analytics teams still route complex queries through a human analyst bottleneck. A jump from 32% to 90% accuracy on heterogeneous lakehouse data is the threshold where “AI-assisted” becomes “AI-delegated” a meaningful shift in how data teams will staff and prioritize work.
The takeaway: If you’re building or evaluating data agents, the architectural bet is no longer single-LLM + RAG; it’s specialist model routing with parallel execution and an eval harness baked in from day one.
Deep Dive
How Databricks Broke the 90% Accuracy Ceiling on Enterprise Data Agents
For years, the honest answer to “can AI query my data warehouse?” was “kind of.” Generic coding agents hit about 32% accuracy on real enterprise datasets good enough for demos, not good enough to trust. In May 2026, the Databricks AI Research team published research explaining how they changed that, and the architecture is worth understanding in detail.
The Problem: Enterprise data environments are fundamentally different from the clean benchmark datasets most coding agents are trained on. A lakehouse can contain millions of assets tables, dashboards, notebooks, semantic models, unstructured documents across SharePoint and Google Drive all with layered business context that isn’t in any schema. A coding agent optimized for GitHub issues simply doesn’t know that your “revenue” column means recognized GAAP revenue and not bookings, or that the right join key changed in Q3 2024 after a migration. Context is everything, and most agents have none of it.
The Solution: The Databricks team redesigned Genie around three interlocking components rather than a single model.
Specialized Knowledge Search: Instead of passing raw table schemas to an LLM, Genie first retrieves semantically relevant documentation, prior queries, column descriptions, and business definitions stored in Unity Catalog. The model sees curated context, not raw metadata dumps reducing hallucination on ambiguous terms dramatically.
Parallel Thinking: For multi-step analytical questions, Genie spins up concurrent reasoning paths rather than a sequential chain-of-thought. Each path explores a different interpretation or approach; the orchestrator selects or merges the best result. This mirrors how a strong analyst actually works: hypothesize, test, revise, not just reason linearly.
Multi-LLM Routing: Not every sub-task needs the same model. SQL generation, semantic disambiguation, chart interpretation, and natural-language summarization are handled by models optimized for each. Routing decisions are made at the query-planning stage, keeping cost and latency in check while maximizing accuracy per task type.
The Results Speak for Themselves:
Baseline: 32% accuracy on internal enterprise data benchmarks using leading single-model coding agents
After Optimization: 90%+ accuracy with the multi-LLM parallel architecture (~180% relative improvement)
Business Impact: Genie Code’s success rate on real-world data science tasks rose from 32.1% to 77.1%, more than doubling autonomous task completion — and Anthropic reported Databricks achieved a 61% reduction in token costs with Opus 4.8 due to multimodal efficiency on PDFs and diagrams
What We’re Testing This Week
Parallel Agent Patterns in Your Own Pipelines
The architectural pattern behind Genie’s accuracy jump parallel reasoning paths with a routing orchestrator is reproducible outside Databricks. Here’s how practitioners are adapting it.
Fan-out / fan-in with asyncio: Instead of
chain.run(query), spawn multiple async tasks with different system prompts (one focused on schema lookup, one on business logic, one on edge-case handling), then merge or vote on outputs. In controlled evals against sequential prompting on multi-step SQL generation, practitioners are reporting 20–40% accuracy gains on ambiguous queries with minimal latency penalty when calls run concurrently.Lightweight model routing via a classifier head: Before hitting your expensive frontier model, run a fast classifier (a fine-tuned Haiku or a local embedding similarity check against a taxonomy) to decide query type. Route
aggregationqueries to a SQL-optimized path,semanticqueries to your RAG pipeline, andhybridqueries to the full multi-LLM stack. The practical tip: start with five query categories maximum; more than that and your classifier overhead starts eating the savings.
Recommended Tools
This Week’s Game-Changers
Databricks Genie Code Agentic data engineering that plans, writes, and executes full pipelines not just autocomplete. More than doubles data science task success rates vs. coding agents. Check it out
Claude Opus 4.8 via API Anthropic’s current top model, scoring 69.2% on SWE-bench Pro and 88.6% on SWE-bench Verified; dynamic workflows now let it orchestrate hundreds of parallel subagents for codebase-scale tasks. Unchanged pricing at $5/$25 per million tokens. Check it out
LLM Stats Benchmark Tracker Real-time leaderboard tracking 500+ models across 50+ benchmarks updated daily with throughput, latency, and pricing from 20+ API providers. Useful for quickly comparing model tradeoffs before committing to an architecture. Check it out
Quick Poll
Lightning Round
3 Things to Know Before Signing Off
Amazon unveils new AI warehouse robot in $12bln Europe push
Amazon unveiled an upgraded AI-powered Proteus robot responding to conversational prompts, part of a €10 billion European fulfillment investment, arriving in Europe by mid-2027.
Meta repeatedly pushes back new AI model release for developers, WSJ says
Meta has repeatedly delayed releasing its new Muse Spark AI model API to developers, with no scheduled launch date as of Tuesday, according to Wall Street Journal reporting.
Australia’s Megaport secures four new AI infrastructure contracts, to raise $594 million
Megaport secured four AI infrastructure contracts worth A$458.9 million with U.S. tech providers, launching a $594 million fundraise to build a globally distributed AI inference cloud starting 2027.