

Hello !!
Welcome to the new edition of Business Analytics Review !
Let's face it, raw data can be really difficult to analyze. It's messy, inconsistent, and often downright unruly. So today, lets dive into the exciting world of Data Wrangling to help you tame that beast and transform it into something beautiful – clean, organized, and ready for analysis.
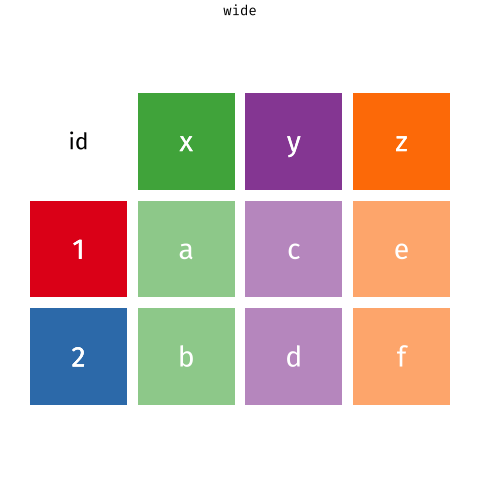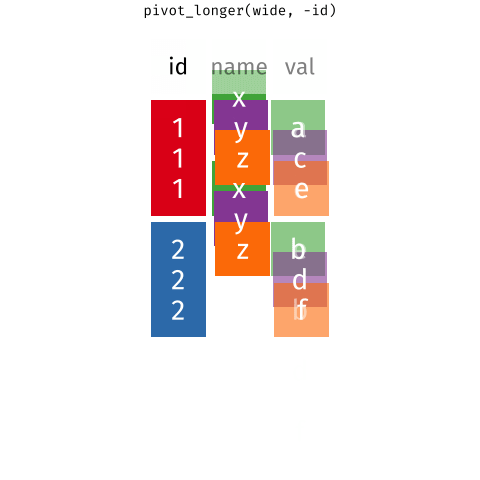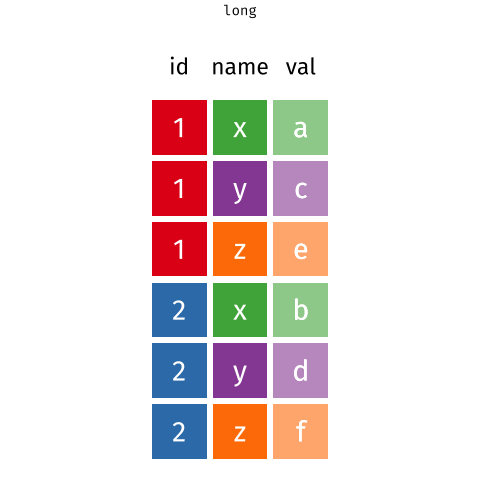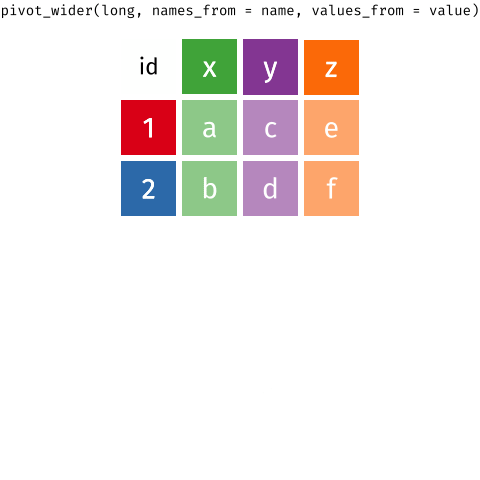
Data wrangling is the art of transforming raw data into a structured format suitable for analysis. It's like turning a pile of scattered puzzle pieces into a complete picture. Let's explore some essential techniques to help you master this crucial step in your data journey.
Data Cleaning
Handling Missing Values: Tackling empty cells.
Outlier Detection: Identifying and dealing with unusual data points.
Data Imputation: Filling in missing values with estimated values.
Data Transformation
Data Normalization: Scaling data to a common range.
Data Aggregation: Combining data points into summary statistics.
Data Reshaping: Converting data from one format to another (wide to long, long to wide).
Data Validation
Data Consistency Checks: Ensuring data integrity and accuracy.
Data Type Conversion: Converting data types as needed (e.g., numeric to categorical).
Imputation Techniques for handling missing values
Deletion: Simply remove rows or columns with missing values. However, this can lead to significant data loss, especially with large amounts of missing data.
Mean/Median Imputation: Replace missing values with the mean or median of the respective column. While simple, it can distort the data distribution.
Mode Imputation: Replace missing categorical values with the most frequent category. Similar limitations to mean/median imputation.
K-Nearest Neighbors (KNN): Impute missing values based on values from similar data points. This method can be more accurate than simple imputation techniques.
Python code for mean imputation
import pandas as pd
import numpy as np
# Load data
data = pd.read_csv('data.csv')
# Check for missing values
print(data.isnull().sum())
# Handle missing values
#(using mean imputation)
data.fillna(data.mean(), inplace=True)
In our last email we talked about Data Visualization. Please read here
Or search ‘businessanalytics@substack.com’ in your mailbox.
Recommended Reads on Data Wrangling
Simple techniques for missing data imputation. A simple imputation, such as imputing the mean, is performed for every missing value in the dataset. These mean imputations can be thought of as “place holders.
Read More
Data transformation refers to the process of cleaning, validating, and preparing data to match that of a target system.
Read More
Data Type Conversion in Python has type conversion routines that allow for the direct translation of one data type to another.
Read More
Latest Insights on Business Analytics
Artificial intelligence has been used to automate business processes and bring efficiencies into companies, reducing their costs in the process.
Read More
How Artificial Intelligence Can Help Give Your Business a Boost.
Read More
CloudOffix Launches Groundbreaking AI Features to Transform Business Operations
Read More
Tool of the Day: PANDAS ( python library )

Pandas is the Swiss Army knife of data manipulation in Python. This powerful library offers versatile tools for handling, cleaning, and exploring datasets of any size. From loading data to complex transformations, Pandas provides the flexibility and efficiency needed to extract meaningful insights. Learn More
If you found this edition valuable, consider gracing us with a like .
We'd love to hear your two cents (or maybe a whole dollar if you really loved it!) in the comments below.
Subscribe & Stay Tuned for the next edition on “Exploratory Data Analysis (EDA)“
STUDY DATA VISUSUALIZATION.
105 Python codes on Data Visualization. Learn More
