
Anthropic Deploys Claude AI Agents to Allen Institute
Edition #251 | 09 February 2026

Anthropic Deploys Claude AI Agents to Allen Institute with Multi-Agent Architecture for Accelerating Scientific Data Analysis
In this edition, we will also be covering:
ElevenLabs secures $11 billion valuation in latest funding round
Musk's mega-merger of SpaceX and xAI bets on sci-fi future of data centers in space
Nvidia-rival Cerebras Systems valued at $23.1 billion in latest financing
Today’s Quick Wins
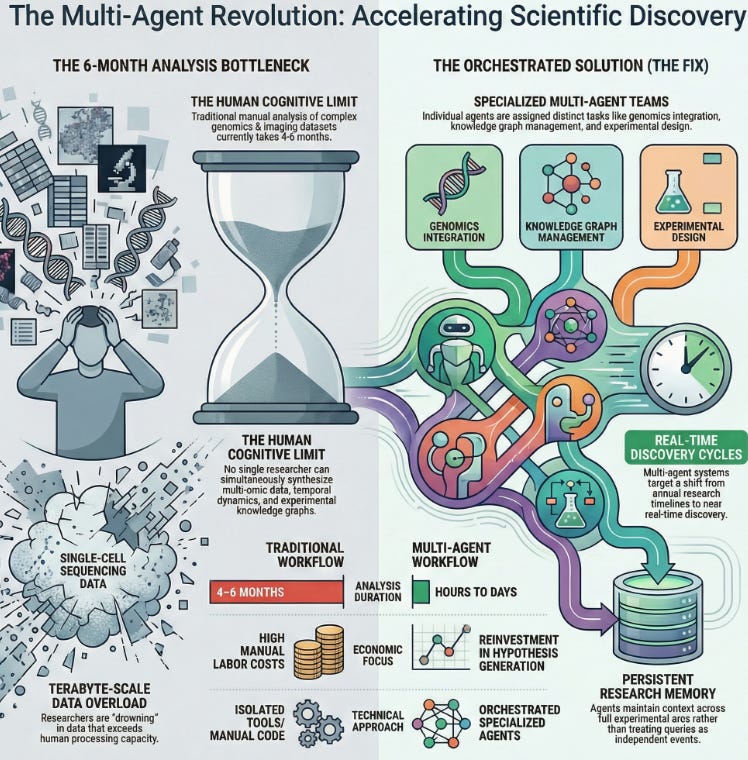
What happened: Anthropic announced flagship partnerships with the Allen Institute and Howard Hughes Medical Institute on February 2nd, embedding Claude-powered AI agents into scientific research workflows. The collaboration targets months-long data analysis tasks involving single-cell genomics, connectomics, and imaging datasets reaching terabytes in scale and aims to compress these into hours using multi-agent systems. The Allen Institute will deploy specialized AI agents for multi-omic data integration, knowledge graph management, and temporal dynamics modeling, while HHMI anchors work at Janelia Research Campus on computational protein design and neural mechanism discovery.
Why it matters: Modern biological research is drowning in data that humans can’t process fast enough. Scientists generate data from single-cell sequencing and whole-brain connectomics at unprecedented scale, but current analysis still depends on manual work that creates a bottleneck lasting months or years. These partnerships flip the economic equation: AI agents now become infrastructure that transforms data-to-insight cycles from annual timelines to near real-time discovery. For data professionals, this represents the shift from building isolated tools to designing coordinated multi-agent systems that handle complex, multi-step research workflows. The emphasis isn’t on replacing human judgment it’s on automating the unglamorous analysis work that prevents discovery.
The takeaway: If you’re building data pipelines or analytics systems, think about how to architect them for multi-agent coordination rather than single-model deployment. The teams winning in 2026 are those treating AI as orchestrated teams of specialized agents rather than monolithic solutions.
Deep Dive
AI Agents Move From Theory to Terabyte-Scale Biology: Why Anthropic’s Scientific Partnerships Matter Now
The headline sounds like academic navel-gazing, but it represents something fundamental shifting in how organizations deploy AI. Anthropic’s announcement isn’t about a faster model or a better benchmark it’s about embedding AI agents directly into the actual workflows where decisions get made.
For two years, we’ve heard the promise that AI could accelerate science. But there’s been a disconnect: the breakthroughs always sound like research papers, while the real bottleneck is the boring stuff. A computational biologist at the Allen Institute still spends months annotating single-cell datasets, running integration pipelines, and hunting for patterns across gene expression matrices that are too big for human intuition to grasp. Meanwhile, generative AI got celebrated for writing emails faster.
Anthropic and these institutions are solving the real problem: turning months of tedious analysis into hours of agent-driven discovery. Here’s the technical shift that matters.
The Problem: Modern biology operates at a scale where traditional analysis breaks down. When you’re processing data from single-cell RNA sequencing across tissues with millions of cells, or whole-brain connectomics mapping billions of neural connections, no single researcher can hold the picture in their head. You need to synthesize data across domains multi-omic integration, temporal dynamics, experimental knowledge graphs simultaneously. Current workflows require humans to write custom code, debug pipelines, manually verify results, and iterate. This stretches research timelines from months into years. The limiting resource isn’t compute anymore; it’s the human bottleneck.
The Solution: Rather than deploying a single large language model and hoping it understands biology, Anthropic’s architecture coordinates multiple specialized AI agents, each optimized for a distinct task in the research pipeline. Think of it as moving from having one brilliant generalist in the lab to assembling a specialized team of agents, each with deep domain knowledge about their particular problem.
Technical Components Driving This Architecture:
Multi-Agent Orchestration: Multiple Claude-powered agents are specialized for different data analysis tasks one handles multi-omic data integration (combining genomics, proteomics, metabolomics), another manages knowledge graph construction and traversal, a third models temporal dynamics across experimental timepoints, and a fourth proposes experimental designs based on discovered patterns. These agents don’t operate in isolation; they pass insights to each other, enabling the kind of cross-domain reasoning that’s impossible with a single monolithic model.
Extended Context and Memory: Rather than treating each query as independent, these agents maintain persistent context about what’s been analyzed, which hypotheses have been tested, and what patterns have emerged. This goes beyond a single conversation window agents remember the arc of a full experiment, enabling them to surface subtle patterns that would disappear if you had to restart analysis fresh.
Tool Integration with Scientific Infrastructure: The agents are wired directly into lab instruments, databases, and analysis pipelines. Instead of a biologist writing Python to extract data from a sequencer or query a database, the agent understands the lab’s technology stack and can autonomously navigate it, run queries, and interpret results in scientific context.
The Results Speak for Themselves:
The partnership announcement doesn’t include exact production numbers yet (these are still in early deployment), but the performance targets are measurable. The Allen Institute previously measured data analysis and annotation bottlenecks at 4-6 months per major research project. The goal is to compress that to the order of days. For researchers like those at Janelia, who are developing new imaging technologies for brain mapping, the ability to analyze connectomics data in real-time rather than months-later changes which experiments become feasible.
The economic impact is substantial: if a $2M grant-funded research project previously spent $400-500K in labor on analysis bottlenecks, those resources now redirect to hypothesis generation and validation. At institutional scale, this represents millions in freed research capacity without hiring additional staff.

💵 50% Off All Live Bootcamps and Courses
📬 Daily Business Briefings; All edition themes are different from the other.
📘 1 Free E-book Every Week
🎓 FREE Access to All Webinars & Masterclasses
📊 Exclusive Premium Content
What We’re Testing This Week
Multi-Agent System Design for Data Analysis Workflows
Most data professionals are still working with single-model deployments, even when they have access to capable LLMs. The real frontier is designing systems where different agents specialize in different parts of your pipeline and coordinate their work.
The challenge is architectural: when you have multiple AI agents operating on the same dataset, you need to think about (1) how they handoff work, (2) how to prevent redundant analysis, (3) how to maintain consistency when agents are working in parallel, and (4) how to surface conflicts when agents reach different conclusions about the same data. Here are two patterns worth experimenting with.
Agent Choreography via Task Graphs: Instead of having agents communicate in natural language, structure their work through explicit task dependency graphs. Define nodes as specific analysis steps (data cleaning, feature engineering, pattern detection, hypothesis generation) and edges as dependencies. Each agent owns a set of nodes and knows which agents produce inputs it needs. This lets you parallelize work, track progress deterministically, and debug failures by node rather than hoping an LLM understood your implicit intentions. Python libraries like Airflow or Prefect handle this, but the pattern matters: move from conversational workflows to explicitly modeled pipelines.
Truth Maintenance Across Agents: When multiple agents analyze the same data, they need a shared source of truth about what’s been discovered. Implement a knowledge store (a graph database or structured knowledge base) that agents write to and read from. Instead of each agent maintaining its own understanding of patterns in your data, they all contribute findings to a single knowledge structure. This reduces hallucination and prevents agents from re-discovering the same insights independently.
Recommended Tools
This Week’s Game-Changers
Claude Code (Anthropic)
Agentic coding interface that lets developers delegate complex analysis tasks directly from their terminal. The Allen Institute reports high adoption among computational biologists who previously wrote custom analysis scripts. Powerful for rapid iteration on data analysis workflows. Access through claude.ai with Code Execution enabled.Check it out
Theorizer (Allen Institute for AI)
Open-source scientific reasoning tool introduced February 2nd, designed for hypothesis generation and experimental design synthesis. Differs from general LLMs by emphasizing logical consistency and falsifiability in scientific contexts. Available on GitHub as part of Ai2’s push toward specialized reasoning systems.Check it out
Multi-Agent Orchestration Patterns (LangChain / LlamaIndex)
Both frameworks now include agent coordination primitives that let you define how multiple AI systems should collaborate. LangChain’s Agent Executor and LlamaIndex’s agent abstractions are production-ready for moderately complex multi-agent workflows. Consider them foundational for building the kind of coordinated systems Anthropic is deploying at research institutions.Check it out
Quick Poll
Lightning Round
3 Things to Know Before Signing Off
ElevenLabs raises $500 million at $11 billion valuation
AI voice synthesis firm ElevenLabs raised $500 million in Series D funding led by Sequoia Capital, boosting its valuation to $11 billion from $3.3 billion. The company reported $330 million annual recurring revenue last year, aiming to double it this year. New investors include Lightspeed and Evantic Capital.
Musk’s mega-merger SpaceX xAI bets on sci-fi future data centers space
SpaceX acquired xAI in a merger valuing the entity at $1.25 trillion, aiming to build orbital data centers to overcome Earth-based power and cooling limits for AI. Elon Musk emphasizes space AI scalability using solar energy. The integration leverages SpaceX’s rockets, Starlink, and funding for off-planet infrastructure.
AI chip maker Cerebras Systems raises $1 billion late-stage funding
Cerebras Systems secured $1 billion in Series H funding led by Tiger Global, achieving a $23 billion valuation to rival Nvidia in AI chips. Investors include Benchmark, AMD, Coatue, and 1789 Capital. The funds support expansion ahead of a potential IPO.
Follow Us:
LinkedIn | X (formerly Twitter) | Facebook | Instagram
Please like this edition and put up your thoughts in the comments.
AI is accelerating discovery
Compressing analysis timelines from months to hours through multi-agent systems is exactly the kind of scientific acceleration that Greg Brockman predicted would be one of the two major themes of 2026. The research velocity implications are significant.
I looked at how Anthropic's positioning in scientific research fits into their broader enterprise strategy: https://thoughts.jock.pl/p/ai-agent-landscape-feb-2026-data