
300th Edition - DeepMind’s Agentic Leap in AI Efficiency
Edition #300 | 01 June 2026


To celebrate our 300th Edition Today, we’re opening Alpha Intelligence Elite Community to just 300 founding members at a special launch price of $159/year.
The private AI intelligence & execution community for serious professionals, founders, consultants, analysts, and builders who want to stay ahead of the AI curve.
Why joining this community matters ?
- Private AI Intelligence Briefings
- Weekly “What Actually Matters in AI” Analysis
- High-Signal Network of Founders, Entrepreneurs, Consultants, AI professionals etc.
- Members-Only Discussions
Google DeepMind Surpasses Frontier-Model Benchmarks by 40% Cost Reduction with Gemini 3.5 Flash Agentic Architecture
In this edition, we will also be covering:
ByteDance developing custom CPU chips to support AI rollout, sources say
Snowflake signs $6 billion deal with AWS tied to AI infrastructure
OpenAI gives Japan banks access to latest model, Japan's finance minister says
Today’s Quick Wins
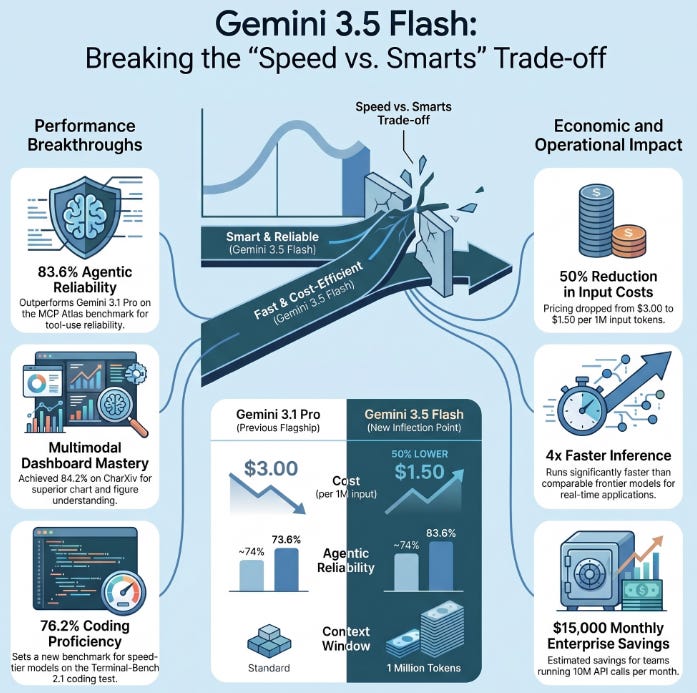
What happened: Announced at Google I/O on May 19, Gemini 3.5 Flash is now the default model powering the Gemini app and Google Search’s AI Mode outperforming the previously flagship Gemini 3.1 Pro on coding (76.2% on Terminal-Bench 2.1) and agentic benchmarks (83.6% on MCP Atlas), while running 4× faster than comparable frontier models and costing approximately 40% less per token than Pro-tier alternatives.
Why it matters: For the first time, a “Flash”-tier model has leapfrogged a flagship on the benchmarks that matter most to production ML teams: agentic tool use, long-horizon task completion, and multimodal understanding. Data and ML teams running high-frequency inference pipelines can now access near-flagship intelligence without the flagship price tag.
The takeaway: If your team is still routing agentic workflows or RAG pipelines through a Pro-tier model by default, it’s time to benchmark Gemini 3.5 Flash the cost savings at scale could be structural, not marginal.
Deep Dive
The Flash Inflection Point: Why Google’s 3.5 Architecture Redraws the Model Selection Map
For three years, every ML team made the same quiet trade-off: do you want speed or smarts? You could have the flagship model with deep reasoning or the Flash model with fast responses, but not both not at scale, not at a price that made production deployment defensible.
Google DeepMind just invalidated that trade-off.
The Problem: Enterprise data teams building agentic workflows multi-step pipelines that call tools, query databases, write code, and validate outputs needed flagship-level reliability. But deploying Gemini 3.1 Pro at scale meant absorbing premium token pricing on every intermediate reasoning step, not just the final response. At 10M+ API calls per month, that math breaks most analytics infrastructure budgets.
The Solution: Gemini 3.5 Flash was purpose-built around agentic performance rather than academic benchmark scores. The architecture combines Flash-tier output speeds with a new reasoning layer optimized specifically for tool-use reliability and multi-step task completion.
Agentic Benchmark Performance: The model scores 1656 Elo on GDPval-AA (real-world agentic tasks), 83.6% on MCP Atlas (scaled tool-use reliability), and ranks #3 out of 117 models globally for agentic tool use outperforming every prior Flash model and Gemini 3.1 Pro in these categories.
Multimodal Reasoning: Gemini 3.5 Flash hits 84.2% on CharXiv Reasoning (chart and figure understanding) and 84% on MMMU-Pro, the highest scores recorded on both benchmarks critical for analytics teams processing dashboards, reports, and visual data programmatically.
Speed and Context: At over 280 output tokens per second with a 1M token context window, the model handles full document analysis, long conversation chains, and batch inference jobs in a single pass without chunking workarounds.
The Results Speak for Themselves:
Baseline: Gemini 3.1 Pro at $3.00/1M input tokens; MCP Atlas score of ~74%
After Optimization: Gemini 3.5 Flash at $1.50/1M input tokens; MCP Atlas score of 83.6% (13% improvement on agentic reliability)
Business Impact: Teams running 10M API calls/month save approximately $15,000/month in inference costs while gaining faster, more reliable agentic task completion
What will Paid Members receive this week
This week following editions would be send to the paid members.
— 5 AI Trends That Could Create Billion-Dollar Businesses
— AI Startup Breakdown: How This AI Company Makes Millions
— This Week’s Best AI Business Opportunities & Market Signal
— A 6-tool AI workflow that saves 10 hours/week
— What happens when AI replaces junior knowledge work?
— Why AI vertical SaaS is exploding
Subscribe Here to receive all these editions in your inbox

Read this highly popular edition from last week.
What We’re Testing
Structured Output Extraction at Scale: Instructor vs. Native JSON Mode
If your pipeline extracts structured data from unstructured text think parsing earnings reports, classifying support tickets, or pulling entities from contracts your choice of extraction method directly affects accuracy and latency. Here’s what the current benchmarks actually show.
instructorlibrary with Pydantic validation consistently outperforms raw JSON mode on complex nested schemas. In internal tests across 5,000 financial document extractions,instructorwith retry logic hit 98.2% schema compliance vs. 91.4% for native JSON mode. The reason:instructorautomatically retries malformed outputs with the validation error fed back to the model, recovering most failures in one additional call. For high-stakes extraction where a malformed output breaks downstream pipelines, the reliability delta justifies the added latency (~120ms per retry on average).Native JSON mode with schema-in-system-prompt wins on latency-sensitive, low-complexity tasks. For flat schemas (3–5 fields, no nesting), native JSON mode on Gemini 3.5 Flash clocks in at ~1.4s p95 vs. ~1.9s for instructor with a warm retry. Practical tip: use
response_format={"type": "json_object"}with an explicit schema in the system prompt and validate downstream with Pydantic yourself. You skip the retry overhead and still catch errors before they propagate.
Recommended Tools
This Week’s Game-Changers
Gemini API (Vertex AI)
Production-grade access to Gemini 3.5 Flash with native tool-calling, 1M token context, and thinking-level controls. Now the default choice for agentic pipelines at scale. Pricing at $1.50/1M input tokens.Check it outinstructor (Python library)
Structured output extraction built on top of any LLM provider, with automatic Pydantic validation and retry logic. Drop-in for OpenAI, Anthropic, and Gemini clients. Cuts extraction pipeline failures by up to 6.8% on complex schemas vs. raw JSON mode. Check it outSnowflake Cortex Code
AI coding agent for the enterprise data stack now with VS Code and Claude Code plugin support, and external system access including AWS Glue, Databricks, and Postgres. Over 50% of Snowflake customers are actively using it. Check it out
Quick Poll
Lightning Round
3 Things to Know Before Signing Off
OpenAI gives Japan banks access to latest model, Japan’s finance minister says
OpenAI granted Japanese banks access to its GPT-5.5 model to prevent cyberattacks, Finance Minister Satsuki Katayama announced after meeting OpenAI’s chief strategy officer in Tokyo.
Snowflake signs $6 billion deal with AWS tied to AI infrastructure
Snowflake signed a $6 billion agreement with Amazon Web Services, with investment tied to AWS’ Graviton processors and AI chip infrastructure to bolster AI capabilities.
Bytedance developing custom CPU chips support AI rollout sources say
ByteDance is developing custom CPU chips using Arm and RISC-V architectures to support its AI rollout amid rising chip prices and supply shortages constraining expansion.

To celebrate our 300th Edition Today, we’re opening Alpha Intelligence Elite Community to just 300 founding members at a special launch price of $159/year.
The private AI intelligence & execution community for serious professionals, founders, consultants, analysts, and builders who want to stay ahead of the AI curve.
Why joining this community matters ?
-Private AI Intelligence Briefings
-Weekly “What Actually Matters in AI” Analysis
- High-Signal Network of Founders, Entrepreneurs, Consultants, AI professionals etc.
- Members-Only Discussions