
Naïve Bayes Classifiers Explained
Edition #292 | 13 May 2026

Hello!
Welcome to today’s edition of Business Analytics Review!
Our focus is on a classic yet incredibly effective algorithm that continues to deliver real business value in 2026: Naïve Bayes Classifiers.
Despite the rise of deep learning models, Naïve Bayes remains a favorite for many practitioners because it’s fast, interpretable, and surprisingly accurate for text-related tasks. Today, we’ll unpack its probabilistic roots, examine its bold independence assumptions, and explore why it excels in spam detection and text classification.
The Probabilistic Foundation of Naïve Bayes
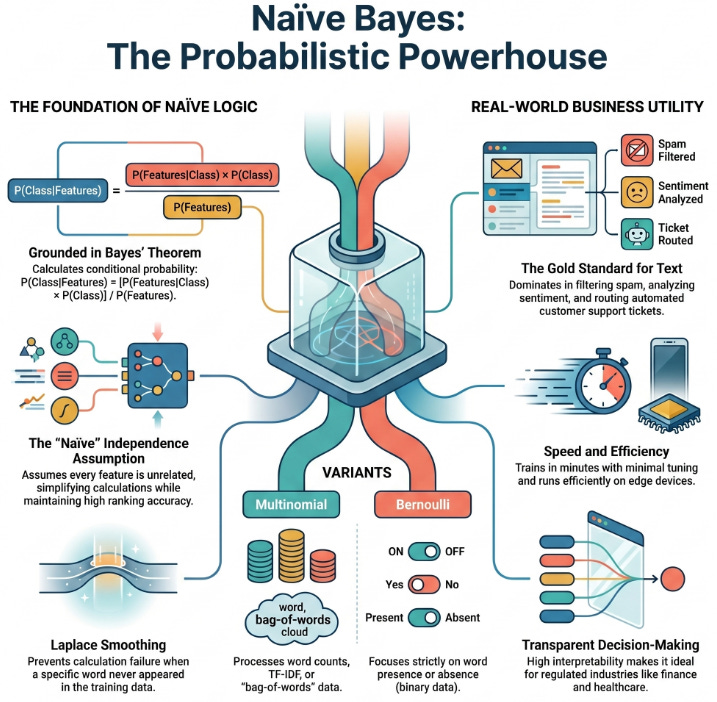
At its core, Naïve Bayes is grounded in Bayes’ Theorem, a fundamental concept in probability theory that helps us calculate conditional probabilities:
P(Class|Features) = [P(Features|Class) × P(Class)] / P(Features)
In simple terms, it answers: “Given the evidence (features like words in an email), what’s the probability it belongs to a particular class (spam or not spam)?”
The algorithm calculates the posterior probability for each possible class and selects the one with the highest value. This makes it a generative classifier it models how the data is generated for each class.
What makes it “naïve”? The strong assumption that all features are conditionally independent given the class label. For example, in a spam email, the presence of “free” is assumed to have no influence on the presence of “winner” once we know it’s spam. In real language, words are correlated, yet this simplification works remarkably well in practice.
Why? Because even when the independence assumption is violated, the probability estimates often rank classes correctly. The model is robust to noisy or redundant features and performs especially well with smaller datasets or high-dimensional spaces exactly what we face in text data.
Real-World Power: Text Classification & Spam Detection
Naïve Bayes shines brightest in text classification. Whether it’s filtering spam, analyzing sentiment, routing customer support tickets, or detecting fake news, the algorithm delivers quick, reliable results.
Take spam detection: The model learns word probabilities from thousands of labeled emails. Words like “viagra,” “urgent,” or “lottery” get higher probabilities in the spam class. When a new email arrives, it multiplies these probabilities (thanks to the independence assumption) and makes a lightning-fast decision.
Multinomial Naïve Bayes works great with word counts (TF-IDF or bag-of-words), while Bernoulli Naïve Bayes focuses on word presence or absence. Laplace smoothing cleverly handles the “zero probability” problem preventing the entire calculation from collapsing if a word never appeared in training data for a class.
A practical anecdote: Many early email providers built their foundational spam filters using probabilistic approaches similar to Naïve Bayes. Even today, companies often use it as a strong baseline or in ensemble systems alongside neural networks. It trains in minutes, needs minimal tuning, and runs efficiently even on edge devices.
Of course, it has limitations. It doesn’t capture feature interactions well and can be overly confident in predictions. Yet its simplicity makes it an excellent teaching tool and a practical choice when explainability matters to stakeholders. In regulated industries like finance or healthcare, being able to clearly explain why a message was flagged as spam carries real value.
When to Choose Naïve Bayes
Use it when you need speed, work with text data, or want an interpretable model. It often outperforms more complex algorithms on small-to-medium datasets and serves as a fantastic benchmark. The combination of strong theoretical roots and practical effectiveness is what keeps this “naïve” algorithm relevant decades after its popularization.
Recommended Reads
Naive Bayes Classifier Explained
Clear breakdown with practical examples and common pitfalls perfect for building intuition. Read MoreNaive Bayes and Text Classification
Excellent theoretical foundation focused on text applications, with mathematical depth. Read MoreIntroduction to Naive Bayes
Hands-on Python implementation that bridges theory and code beautifully. Read More
Trending in AI and Data Science
Let’s catch up on some of the latest happenings in the world of AI and Data Science
Pentagon deploys Anthropic’s Mythos to patch cyber gaps while planning to ditch firm
The Pentagon is actively deploying Anthropic’s Mythos cybersecurity model to identify and fix software vulnerabilities across U.S. government systems, according to the Defense Department’s top technology official. Mythos launched April 7 as part of Project Glasswing, allowing select organizations temporary access to the unreleased Claude Mythos Preview for defensive security purposes only
OpenAI gives European companies access to its latest models to bolster resilience
OpenAI has granted European companies access to its newest artificial intelligence models to strengthen cybersecurity resilience across the continent. The move is part of the OpenAI EU Cyber Action Plan, which aims to democratize AI access for European policymakers, institutions, and businesses
Google thwarts first AI-generated zero-day exploit
Google’s Threat Intelligence Group confirmed what it calls the first known case of hackers using artificial intelligence to develop a zero-day exploit for a planned cyberattack. The AI-assisted flaw could bypass two-factor authentication on an open-source web administration tool. Attackers intended mass exploitation before Google detected and stopped the activity, marking the first tangible evidence of AI-assisted zero-day weaponization by cybercriminals
Trending AI Tool: PandasAI

PandasAI continues to gain popularity among analysts and data scientists. It supercharges your pandas DataFrames by letting you ask questions in natural language (“What was the month-over-month growth in marketing spend?”) and returns insights instantly using LLMs.
`Learn more.