
Introduction to Neural Network Architecture
Edition #280 | 15 April 2026

Nearly 9 of 10 fraud perpetrators show GLARING warning signs before detection. So why do most organizations still get blindsided?

Research across fraud cases, email behavior, and organizational network analysis shows early signals often precede turnover, misconduct, disputes, and other workplace crises. This report examines the data behind those patterns and reveals how businesses can better position themselves to spot them.
The Story of Neural Networks: From a Single Neuron to Billion-Parameter Models
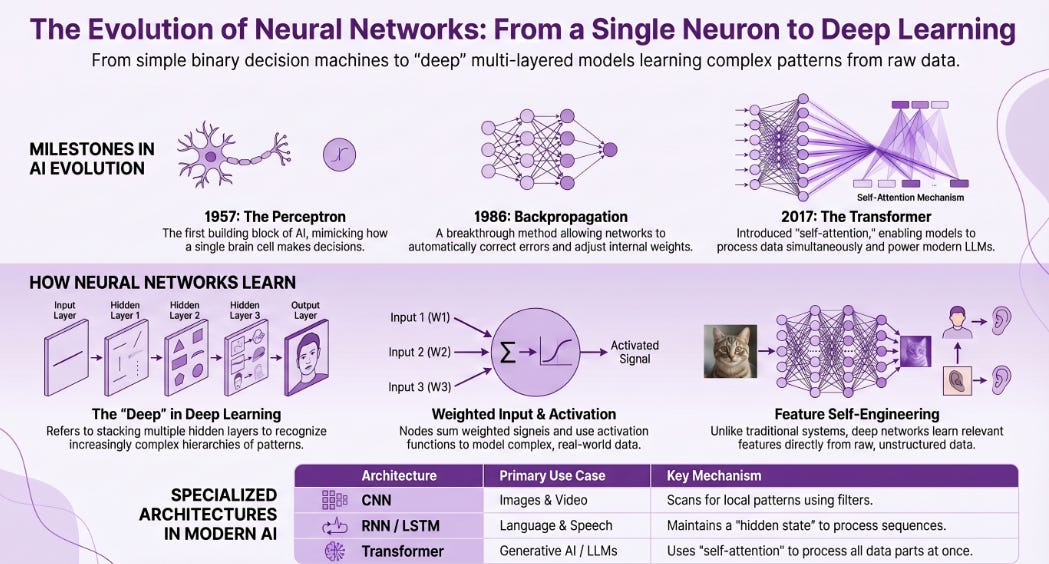
It’s easy to look at modern AI — the systems that write code, generate images, translate languages, and predict protein structures — and assume it all sprang from some recent technological leap. But the truth is far more interesting. The foundation of what we now call deep learning was laid over 70 years ago, with a deceptively simple idea: what if a machine could mimic the way a single brain cell makes a decision?
That question led to the perceptron, and from there, to one of the most consequential technological journeys in human history.
It All Started with a Neuron
The human brain contains roughly 86 billion neurons. Each one receives signals, does a bit of processing, and either fires or doesn’t — passing information downstream. When AI researchers in the 1950s began thinking about how to replicate intelligence computationally, this biological model became their blueprint.
In 1957, a psychologist and computer scientist named Frank Rosenblatt introduced the perceptron — arguably the first building block of modern AI. The concept was elegant: take a set of inputs, assign a weight to each one (representing importance), sum them up, and if that sum crosses a threshold, the perceptron “fires” — outputting a 1 instead of a 0. It was, at its core, a binary decision machine.
“The perceptron is the simplest neural network — a linear classifier that maps inputs to an output through a weighted sum followed by an activation function. Simple as it sounds, it laid the conceptual groundwork for everything that followed.”
To picture it concretely: imagine you’re trying to decide if an email is spam. The perceptron looks at signals like “Does it contain the word ‘free’?” (weight: high) or “Is the sender in your contacts?” (weight: low, negative). It sums those weighted signals, compares to a threshold, and gives you a yes or no. Clean, fast, interpretable.
But here’s the problem — and it’s a famous one. In 1969, AI pioneers Marvin Minsky and Seymour Papert demonstrated in their book Perceptrons that a single-layer perceptron fundamentally couldn’t solve problems that aren’t linearly separable. The classic example is the XOR problem: no single straight line can cleanly separate two classes in that arrangement. This revelation triggered what became known as the first “AI winter” — a period of deflated enthusiasm and reduced funding.
The Road Through the Winters
Progress didn’t stop entirely, though. Researchers kept asking: what if you stacked multiple perceptrons together — hidden layers between input and output? What if you could teach the network which weights were contributing to errors and correct them automatically? The theoretical groundwork was being laid, even if the hardware wasn’t ready yet.
Key Milestones in Neural Network History
1957 - Frank Rosenblatt introduces the Perceptron at Cornell Aeronautical Laboratory — physically built as a machine, capturing national media attention.
1986 - Rumelhart, Hinton, and Williams popularize Backpropagation — enabling effective training of multi-layer networks by calculating each weight’s contribution to errors
2012 - AlexNet wins the ImageNet competition by a massive margin. Deep learning is suddenly, undeniably real — and the modern AI era begins
2017 - Google researchers publish “Attention Is All You Need”, introducing the Transformer architecture that powers every major LLM today
Today - Models with hundreds of billions of parameters operate across text, image, code, and audio — deployed at scale and evolving faster than anyone predicted.
What’s Actually Inside a Neural Network?
Before we get to the deep end of the pool, it’s worth making sure the anatomy is clear. A neural network — at its most basic — is a stack of layers. Each layer is a collection of nodes (artificial neurons), and each node is connected to the nodes in the layer before and after it by edges with weights.
[Input Layer] → [Hidden Layer 1] → [Hidden Layer 2] → [Output Layer]
x₁, x₂, x₃ h₁, h₂, h₃, h₄ h₁, h₂, h₃, h₄ y₁, y₂
↑ ↑
Raw inputs Final predictions
(e.g. pixel values) (e.g. "cat" or "not cat")A simple feedforward neural network — information flows left to right, with no loops.
Here’s how data actually moves through this structure. You feed in your inputs — say, pixel values from an image. Each node computes a weighted sum of its inputs, adds a bias term, and then passes the result through an activation function. The activation function is crucial: without it, every layer would just be doing linear math, and stacking a thousand linear transformations is still just one linear transformation. Activation functions like ReLU (Rectified Linear Unit) introduce the non-linearity that lets networks model complex, real-world patterns.
The network then compares its output to the correct answer, calculates an error using a loss function, and through the magic of backpropagation, adjusts every weight slightly in the direction that reduces that error. Do this millions of times on millions of examples, and the network gradually learns to perform the task it was trained on.
Why “Deep” Learning?
The “deep” in deep learning simply refers to the number of hidden layers — but that depth is what makes everything interesting. Shallow networks learn simple patterns. Deeper networks learn hierarchies of patterns.
Take image recognition as an example. The first layer of a deep network might learn to detect simple edges and color contrasts. The second layer combines those into textures and simple shapes. By the fifth or sixth layer, the network is recognizing features like “eyes” or “wheels.” By the final layers, it’s outputting confident predictions: “That’s a cat.” Each layer builds on abstractions from the previous one — almost exactly the way the human visual cortex is believed to process visual information.
💡 Why this matters for business: This is why deep learning is so powerful for tasks involving unstructured data — images, audio, text. Unlike traditional machine learning, which required human experts to manually engineer features, deep networks learn the relevant features directly from raw data. The model figures out what matters.
The Architectures That Changed Everything
Once the deep learning wave broke in the early 2010s, specialized architectures began emerging to handle different kinds of data. Three in particular stand out:
1. Convolutional Neural Networks (CNNs)
Designed for grid-like data (images, video), CNNs use a convolution operation to scan for local patterns using small learnable filters. They’re what powers face recognition on your phone, defect detection on factory floors, and medical imaging analysis in hospitals.
2. Recurrent Neural Networks (RNNs) & LSTMs
Traditional feedforward networks treat every input independently. But language, time series data, and speech are sequential — each word or data point relates to what came before. RNNs maintain a hidden state that carries information forward through the sequence. Long Short-Term Memory networks (LSTMs) extended this to capture long-range dependencies that vanilla RNNs struggled with.
3. Transformers
The architecture that dominates AI today. Rather than processing sequences step by step, Transformers use a mechanism called self-attention to look at all parts of an input simultaneously, learning which parts are relevant to each other. This parallelism also made them dramatically easier to scale with larger datasets and more compute — which is exactly why today’s large language models are so capable.
Where We Are Now
It’s worth pausing to appreciate just how far this has come. From Rosenblatt’s perceptron — which could barely classify straight lines — to models with hundreds of billions of parameters that write essays, analyze medical scans, predict the folding of proteins, and power real-time translation across 100+ languages. The jump is staggering.
And the evolution hasn’t stopped. Graph Neural Networks are now being used to model molecular interactions and social networks. Hybrid architectures combine symbolic reasoning with neural processing. Researchers are exploring neuromorphic computing — chips that more closely replicate biological neurons. The perceptron was the first step on a path that, 70 years later, still has no visible end.
For anyone working in business analytics, data science, product, or strategy — understanding this architecture isn’t just academic curiosity. It’s the foundation of every AI product you’re evaluating, deploying, or competing against. The more fluent you are in these ideas, the better your decisions will be.
Recommended Reads
Neural Networks: From Perceptrons to Deep Learning
A thorough technical walkthrough tracing the full evolution from Rosenblatt’s perceptron to modern deep architectures — complete with mathematical notation, architecture comparisons, and real-world application examples across computer vision, NLP, and healthcare. Read MoreThe Essential Guide to Neural Network Architectures
A well-structured guide covering every major neural network architecture — from feedforward networks and CNNs to ResNets — with clear explanations of activation functions, layer design decisions, and practical guidance on when to use each architecture type. Read More
Neural Networks and Deep Learning: A Comprehensive Introduction
A hands-on introduction that bridges theory and practice — covering the biological inspiration behind artificial neurons, multi-layer perceptron implementation using Keras, and hyperparameter tuning strategies, making it ideal for readers ready to write their first deep learning code. Read More
Trending in AI and Data Science
Let’s catch up on some of the latest happenings in the world of AI and Data Science
Alibaba Leads $300 Million Bet on AI Video Generator ShengShu
Alibaba’s cloud division led a 2 billion yuan ($293M) funding round for Beijing-based ShengShu Technology, maker of Vidu AI video generator. Backed also by Baidu Ventures and Luminous Ventures, this follows their recent 600M yuan raise amid China’s AI video competitionVance, Bessent Questioned Tech Giants on AI Security Before Anthropic’s Mythos
US Vice President JD Vance and Treasury Secretary Scott Bessent quizzed tech CEOs on AI security and cyber threats just before Anthropic released Mythos. Discussions highlighted risks from powerful AI models amid rising concernsWhy Officials Are So Worried About Mythos, Anthropic’s New AI
Anthropic’s Mythos AI, capable of exploiting hidden software flaws across OS and browsers, alarms US officials like Bessent and Powell. Limited initial release to firms like Amazon, Apple, JPMorgan via Project Glasswing to bolster defenses in cyber arms race
Trending AI Tool: Blink - AI Powered News

Blink by After Hour Studio – the ultimate tool to make your words impossible to ignore! Instantly create eye-catching blinking text and hypnotic animations. Customize speed, style, and intensity in seconds, then copy ready-to-use HTML/CSS code. Turn boring text into attention-grabbing magic for your website, banners, or projects. Learn More
Follow Us:
LinkedIn | X (formerly Twitter) | Facebook | Instagram
Please like this edition and put up your thoughts in the comments.
I appreciate the history lesson with the architecture explanation. Cheers!
I loved the post and thank you for the reading recommendations, I will check them out.