
FREE : Autoencoders for Dimensionality Reduction and Anomaly Detection
Edition #304 | 10 June 2026

Hello!
Welcome to today’s edition of Business Analytics Review!
Let’s start with a little thought experiment. Imagine you have a 10,000-piece jigsaw puzzle in front of you. Now, someone asks you to describe it using only 50 words and then reconstruct the full picture from those 50 words. Hard, right? That’s precisely the challenge autoencoders take on every single day and they’re remarkably good at it.
Autoencoders are a family of neural networks trained to do something deceptively simple: compress data into a compact form, then rebuild it as faithfully as possible. But buried inside that process is something genuinely powerful the ability to learn the essence of data, and flag anything that doesn’t quite belong.
"An autoencoder doesn't just reduce data it forces the model to discover what truly matters, and in doing so, reveals what's genuinely unusual."
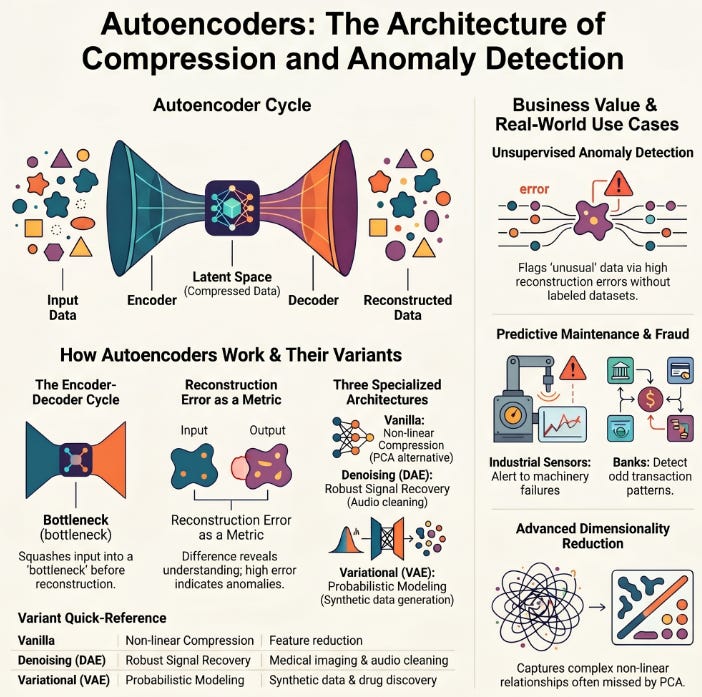
Today, we're going to walk through how these architectures actually work, look at the three most important variants the vanilla, denoising, and variational autoencoder and explore where they're showing up in real industry applications.
The Architecture
How Does an Autoencoder Actually Work?
At its core, an autoencoder has two parts: an encoder and a decoder. Think of the encoder as a very efficient compressor. It takes your high-dimensional input say, a medical image with thousands of pixels and squashes it into a much smaller representation called the latent space (sometimes called a bottleneck layer). The decoder then takes that compressed representation and tries to reconstruct the original input.
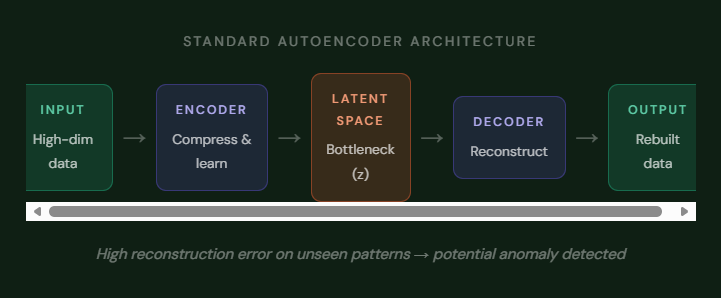
Training the model means minimizing the difference between the original input and the reconstructed output a loss called reconstruction error. Once trained on “normal” data, anything unusual will produce a much higher reconstruction error, because the network never learned how to compress and rebuild it. That, in a nutshell, is anomaly detection via autoencoders.
The Three Variants
Vanilla, Denoising & Variational — What Sets Them Apart?
Not all autoencoders are created equal. Over the years, researchers have refined the basic architecture into specialized forms that tackle specific challenges. Here are the three you’ll encounter most often in real-world ML pipelines:
Variant
The Vanilla Autoencoder
This is the original blueprint a straightforward encoder-decoder pair connected by a bottleneck. It’s trained to reconstruct inputs as accurately as possible by minimizing reconstruction error. It performs remarkably well for basic dimensionality reduction: think PCA, but with the ability to capture non-linear relationships in data. Where linear methods like PCA draw straight lines through data, the vanilla autoencoder can bend and curve its way to more accurate representations.
Best for: Feature compression & basic anomaly scoring
Variant
The Denoising Autoencoder (DAE)
Here’s where things get clever. Instead of feeding the model clean data, a DAE deliberately corrupts the input adding noise, masking portions, or introducing distortions and then asks the network to reconstruct the original, clean version. The result? A model that’s far more robust. It learns to distinguish the true signal from noise, making it incredibly useful for tasks like audio cleaning, medical image enhancement, and critically more resilient anomaly detection in messy, real-world data.
Best for: Noisy data, signal recovery & robust anomaly detection
Variant
The Variational Autoencoder (VAE)
The VAE is where autoencoders meet probability theory. Instead of compressing data into a single fixed point in latent space, the VAE encodes it as a probability distribution specifically, a mean and variance. During decoding, it samples from this distribution to reconstruct the input. This probabilistic twist does two extraordinary things: it makes the latent space smooth and continuous (enabling realistic data generation), and it provides a natural anomaly score based on how far a sample deviates from the expected distribution. VAEs underpin many modern generative AI applications, from drug discovery to synthetic data creation.
Best for: Generative modeling, probabilistic anomaly scoring & data synthesis
The Core Application
Anomaly Detection: Where Autoencoders Really Shine
Let’s get practical. Why does any of this matter for business analytics and AI applications? The answer lies in one of the most economically valuable problems in technology today: catching the unusual before it becomes costly.
The Logic Behind Autoencoder-Based Anomaly Detection
Train the autoencoder exclusively on normal, healthy data. Since the model learns a compressed representation built entirely around normality, it becomes quite good at reconstructing normal inputs but struggles with anything it hasn’t seen before. An anomalous input gets poorly reconstructed, generating a high reconstruction error. Set a threshold on that error, and you have a principled, unsupervised anomaly detector no labels required.
This is powerful because in the real world, labelled anomaly data is scarce. Fraud cases, machine failures, network intrusions these are rare events by definition. Autoencoders sidestep this limitation entirely by learning only from the normal cases, which are almost always abundant.
Real-World Applications
Financial Fraud Detection
Banks train autoencoders on millions of normal transactions. Unusual patterns odd amounts, foreign geolocations, atypical timing generate spikes in reconstruction error, flagging potential fraud in real time.
Predictive Maintenance
Sensor data from industrial machinery is fed to autoencoders. When vibration or temperature patterns deviate from the learned normal profile, an alert fires often days before mechanical failure.
Medical Imaging
Trained on healthy MRI scans, denoising autoencoders can both improve image quality and flag regions that reconstruct poorly acting as a first-pass screening tool for radiologists.
Cybersecurity (IDS)
Network traffic autoencoders learn the “fingerprint” of normal activity. Intrusions, DDoS patterns, or data exfiltration attempts generate anomalously high reconstruction errors, triggering alerts.
The Other Superpower
Dimensionality Reduction Done Differently
Beyond anomaly detection, autoencoders are increasingly replacing or complementing classical dimensionality reduction techniques like PCA and t-SNE in production ML pipelines. The key advantage? They learn non-linear relationships in data that linear methods simply cannot capture.
Consider a retail company sitting on a dataset with 500 product features per customer interaction. Training downstream recommendation or classification models directly on 500 features is computationally expensive and prone to the curse of dimensionality. Pass that data through a trained autoencoder’s encoder, extract the 20-dimensional latent vector, and suddenly your downstream model trains faster, generalizes better, and often performs comparably or even stronger.
This is the quiet, behind-the-scenes role autoencoders play in modern ML pipelines not always the star of the show, but often the reason the star performs so well.
Closing Thought
A Tool Worth Understanding Deeply
The beauty of autoencoders lies in their elegant simplicity at the conceptual level compress, reconstruct, measure the gap combined with a surprising depth of nuance in practice. Choosing between vanilla, denoising, and variational architectures isn’t just a technical decision; it’s a reflection of what you value most in your model: simplicity, robustness, or probabilistic expressiveness.
Whether you’re building a fraud detection system, a predictive maintenance pipeline, or a generative model for drug discovery, there’s almost certainly an autoencoder variant suited to your problem. And as unsupervised learning continues its ascent in the AI landscape driven by the growing scarcity of labeled data autoencoders will only become more central to the toolkit.
Until next time, keep analyzing, keep building, and keep asking: “What does the data consider normal?”
Recommended Reads
Leveraging Autoencoder Techniques for Anomaly Detection and Data Denoising
A step-by-step practical guide covering real-world implementation strategies, preprocessing techniques, and best practices for deploying autoencoders in anomaly detection and denoising workflows. Read MoreDemystifying Neural Networks: Anomaly Detection with AutoEncoder
A clear, code-accompanied walkthrough of how to build an anomaly detection system using autoencoders on real datasets bridging theory and implementation beautifully. Read MoreAutoencoders for Dimensionality Reduction, Feature Extraction
A comprehensive walkthrough of autoencoder types vanilla, convolutional, variational, and sparse with Python/Keras code and discussion of when and why to use each variant. Read More
Trending in AI and Data Science
▸ Anthropic releases Claude Fable 5, its most capable model with built-in safety limits
Read More
▸ Google upgrades NotebookLM with agentic chat and advanced multi-step reasoning
Read More
Trending AI Tool: Weights & Biases (W&B)

If you're training autoencoders or any neural network you've probably faced the maddening experience of losing track of which experiment configuration produced your best results. Weights & Biases (W&B) solves this problem elegantly. It automatically logs your hyperparameters, reconstruction loss curves, latent space visualizations, and model artifacts in real time, giving you interactive dashboards to compare runs side by side.
Learn more.