
Database Indexing Techniques
Edition #246 | 28 January 2026

Hello!
Welcome to today’s edition of Business Analytics Review!
Your daily dose of insights into the fascinating world of Artificial Intelligence and Machine Learning. I’m thrilled to dive deeper into a topic that’s at the heart of efficient data handling Database Indexing Techniques, with a special focus on Improving Query Performance. Whether you’re a seasoned data scientist tweaking ML models, a business analyst crunching numbers for strategic decisions, or even a newcomer curious about how data flows in AI systems, understanding how to make your queries zip along can save you time, resources, and a whole lot of frustration. Let’s chat about this in a way that feels like we’re grabbing coffee and geeking out over databases, unpacking the nuances with more examples and insights to make it all click.
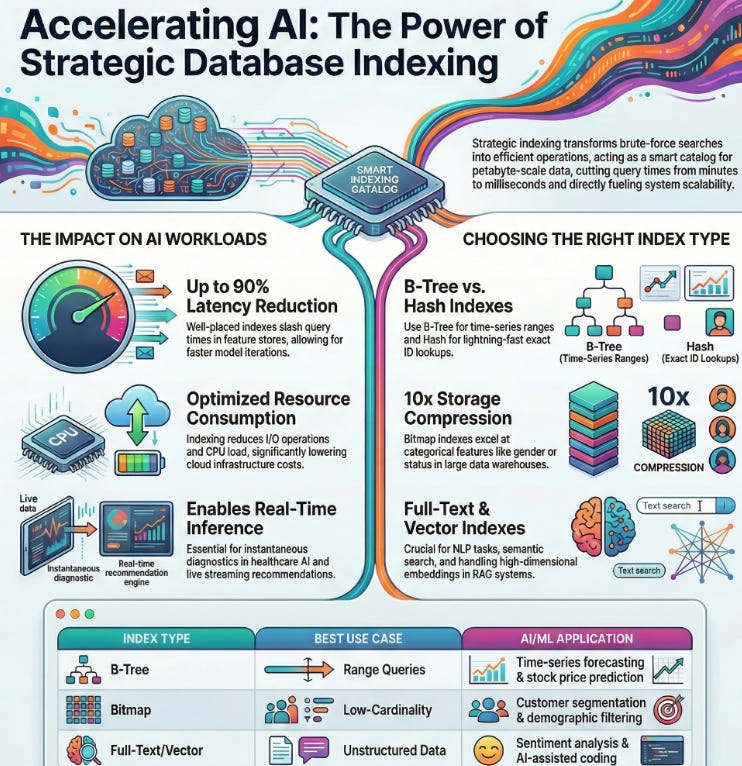
Why Database Indexing Matters in AI and ML
Picture this: You’re building an AI recommendation system for an e-commerce platform, sifting through millions of user interactions to suggest the perfect product. Without proper indexing, your database is like a massive library with no catalog every search means flipping through every book, page by page. Indexing acts as that smart catalog, pointing your queries straight to the right shelves, dramatically reducing the time and computational effort needed. In the realm of AI and ML, where datasets are exploding in size and complexity think petabytes of sensor data for autonomous vehicles or vast corpora for natural language processing effective indexing isn’t just a nice-to-have; it’s essential for training models faster, running real-time inferences, and keeping cloud costs in check. I’ve seen teams cut query times from minutes to milliseconds just by rethinking their indexes, turning sluggish apps into responsive powerhouses. For instance, in healthcare AI, where querying patient records for predictive analytics must be instantaneous to aid real-time diagnostics, poor indexing could mean delayed insights that impact lives. On the flip side, companies like Google leverage sophisticated indexing in their search algorithms to handle trillions of queries, blending ML with database smarts for lightning-fast results.
How Indexing Boosts Query Performance
At its core, indexing creates a structured shortcut for your database to locate data without scanning every row, much like how a book’s index lets you jump to specific topics without reading cover to cover. When you query a database, an index allows the system to jump directly to relevant records, slashing I/O operations (that’s input/output for the uninitiated) and CPU load by orders of magnitude. For instance, in machine learning pipelines, where you’re constantly querying feature stores for training data say, pulling user behavior logs for a churn prediction model a well-placed index can reduce latency by up to 90%, allowing more iterations in your experiments. But it’s not magic; over-indexing can slow down write operations because every insert or update requires index maintenance, so it’s about striking that balance tailored to your read-write ratio. In industry terms, giants like Netflix use advanced indexing to handle billions of daily queries, ensuring seamless streaming recommendations powered by ML algorithms that analyze viewing patterns in real time. Another angle: In edge AI applications, like IoT devices processing sensor data, efficient indexing minimizes energy consumption, extending battery life while maintaining performance. The key takeaway? Indexing transforms brute-force searches into elegant, efficient operations, directly fueling the scalability of AI systems.
Common Types of Database Indexes
Let’s break down the main players in indexing, each suited to different scenarios in AI-driven applications, with a bit more on how they operate and when to choose them:
B-Tree Indexes: The go-to for most relational databases like PostgreSQL or MySQL. They’re balanced trees (hence B-Tree) that maintain sorted data, excelling in range queries, such as fetching all user data between certain dates or scores in a leaderboard for gamified ML apps. In ML, they’re handy for time-series data in forecasting models, like predicting stock prices, where you often query historical ranges. The structure ensures logarithmic time complexity, making them reliable for large datasets.
Hash Indexes: Perfect for exact-match lookups, like finding a specific user ID in a recommendation engine or hashing keys in distributed systems. They’re lightning-fast for equality checks think O(1) average time but falter on ranges or inequalities, so they’re ideal for key-value stores in NoSQL setups like Redis, often used in caching ML inference results. A caveat: They can degrade with hash collisions in high-volume AI workloads, so monitor your data distribution.
Bitmap Indexes: Ideal for low-cardinality columns (think gender, status flags, or categorical features like product categories) in data warehouses like Snowflake. They compress data into bitmaps, enabling bitwise operations for ultra-efficient analytical queries in BI tools integrated with AI insights. For example, in customer segmentation ML models, querying demographics across millions of records becomes a breeze, often compressing storage by 10x compared to other indexes.
Full-Text Indexes: A boon for NLP tasks in ML, allowing fuzzy searches on text data, like querying customer reviews for sentiment analysis or searching code repositories for similar snippets in AI-assisted coding. They use inverted indexes to handle stemming, synonyms, and relevance ranking, much like search engines, making them indispensable for unstructured data in AI pipelines.
Choosing the right type depends on your workload analyze your query logs first. I once worked on a project where switching to bitmap indexes for a categorical feature in a fraud detection model halved our query times and reduced storage costs, turning a resource hog into a lean machine real-world wins like that make this stuff exciting!
Best Practices for Implementing Indexes
To truly amp up performance, it’s not just about slapping on indexes; it’s strategic and iterative. Start by analyzing your query patterns using tools like EXPLAIN in SQL or query analyzers in MongoDB identify slow queries and index the columns they frequently filter, join, or sort on, prioritizing those with high selectivity (unique values) to maximize gains. Avoid indexing every column; that leads to bloat and slower inserts aim for a read-optimized setup if your AI app is query-heavy, like in dashboards for ML monitoring. Regularly maintain indexes by rebuilding or reorganizing them to handle fragmentation, especially in high-write environments like real-time ML inference systems where data streams in continuously. Don’t forget composite indexes for multi-column queries they combine fields into one index, boosting compound conditions, such as querying by user ID and timestamp in session-based recommenders. In the AI space, integrating indexing with vector databases for similarity searches (using techniques like HNSW or IVF) is becoming crucial for handling embeddings in semantic search or RAG (Retrieval-Augmented Generation) systems. Monitor with metrics like index usage stats and cache hit rates tools like pgBadger for Postgres can reveal underused indexes to drop. And always test in staging; I recall a case where an overlooked index on a join column sped up a batch ML training job from hours to minutes, freeing up the team for more innovative work.
Recommended Reads
Boost Query Performance with Database Indexing
Expert Strategies from Acceldata dives into creating strategic indexes on queried columns to cut resource use. Check it outDatabase Indexing Basics
How Indexes Make Queries Faster by Upsun a beginner-friendly guide to B-tree, hash, and full-text indexes for app speed. Check it outOptimizing Database
Performance with Effective Indexing Strategies from CloudThat covers indexing types, strategies, and best practices for efficient implementation. Check it out
Trending in AI and Data Science
Let’s catch up on some of the latest happenings in the world of AI and Data Science
Nvidia unveils AI models for faster, cheaper weather forecasts
Nvidia released three open-source AI models at the American Meteorological Society meeting to improve weather forecasting speed and accuracy. These models replace costly simulations, run faster post-training, and aid insurance for extreme events like floods.Google Android Told by EU to Open Up to Rival AI Systems
The EU gave Google six months to remove Android barriers for rival AI search assistants and share search data under DMA rules. This promotes interoperability and fair access amid Big Tech scrutiny.Honeywell Sees Growing Market for ‘Physical AI’ Use in Buildings
Honeywell highlights physical AI’s rise for building efficiency in airports and hospitals, shifting from pilots to 200,000+ global sites. It optimizes workflows and energy amid net-zero demands.
Trending AI Tool: Pinecone

Wrapping up today’s edition, I’d like to spotlight a trending AI tool that’s making waves in data management: Pinecone. This fully managed vector database is designed for real-time AI applications, offering low-latency search and advanced indexing for high-dimensional data like embeddings from ML models. It’s perfect for building scalable recommendation systems or semantic search features, with features like hybrid search that blend keyword and vector indexing for even better performance.
Learn more.