
Data Preprocessing Techniques
Edition #205 | 22 October 2025


Vibe Coding Certification - Live Online
Weekends Sessions | Ideal for Non Coders | Learn to code using AI
Hello!
Welcome to today’s edition of Business Analytics Review!
Today, in our dive into Data Preprocessing Techniques, we’re zeroing in on the unsung heroes: cleaning, normalization, and transformation methods. These steps turn raw, messy data into something your algorithms can savor, boosting accuracy and efficiency.
I’ve been knee-deep in ML projects for years, and let me tell you, skipping preprocessing is like building a house on sand. One time, early in my career, I fed unnormalized customer data into a clustering model for a retail client. The results? A hilarious mess where high-value shoppers got lumped with outliers because their spending figures dwarfed everything else. Lesson learned: Prep your data like you mean it. Let’s break it down conversationally, shall we?
Why These Techniques Matter and the Evolving Landscape
In the fast-paced world of AI-driven decisions from predicting churn in telecom to optimizing supply chains in e-commerce garbage in means garbage out. Cleaning removes the noise, normalization levels the playing field, and transformation reshapes data to fit your model’s needs. According to industry reports, well-preprocessed data can improve model performance by up to 20-30%, saving companies thousands in misguided strategies. It’s not just technical wizardry; it’s essential for ethical, scalable analytics.
Data preprocessing remains the bedrock of successful AI and ML initiatives, often consuming 60-80% of project time according to veteran practitioners. In 2025, with datasets ballooning from IoT sensors and real-time streams, these aren’t optional steps they’re vital for handling everything from multimodal data to edge computing demands. Whether you’re chaining them in automated pipelines or tweaking on the fly, mastering this feels like gaining a secret edge. Let’s unpack each one with a blend of basics and advanced tactics to get you workflow-ready.
Cleaning: The Art of Decluttering Your Dataset, from Basics to Advanced Strategies
Think of cleaning as tidying up before guests arrive. Raw data often comes loaded with duplicates, missing values, outliers, and inconsistencies like multiple spellings of “New York” or blank entries for customer ages. But cleaning extends far beyond simple deletions; it’s about anomaly detection and preserving variability for robust models.
Start with the fundamentals:
Handling Missing Values: You can’t ignore them; impute with means, medians, or even advanced methods like KNN imputation. For instance, in a healthcare dataset, guessing a patient’s blood pressure from similar profiles beats dropping the row entirely.
Removing Duplicates and Outliers: Tools like Python’s Pandas make this a breeze with drop_duplicates(). Outliers? Use IQR or z-scores to spot them remember that one rogue sales figure from a data entry error that could skew your revenue forecast?
For deeper dives, consider anomaly detection using isolation forests or DBSCAN clustering to flag sophisticated outliers, not just statistical ones. For missing data, forward-fill suits time-series (e.g., stock prices), while multiple imputation via MICE preserves variability in surveys. In regulated sectors like finance, always log your transformations for audit trails to ensure compliance.
Here’s a quick comparison to guide our choices:

Insightful Tip and Anecdote: In a recent project for a fintech firm, aggressive cleaning reduced our dataset by 15% but lifted prediction accuracy from 72% to 89%. And get this a logistics giant I consulted for used fuzzy matching to merge 2M+ duplicate shipment entries, slashing query times by 40% and uncovering $500K in overlooked efficiencies. It’s tedious, but oh-so-rewarding. Validate with cross-validation scores pre- and post-prep to quantify those lifts.
Normalization: Making Apples-to-Apples Comparisons, with Scaling Nuances
Different features on wildly different scales? That’s a recipe for biased models. Normalization squeezes everything into a common range, usually 0 to 1, via min-max scaling: (x - min) / (max - min). Standardization (z-score) centers data around mean 0 and std 1, ideal for algorithms like SVM or neural nets sensitive to variance.
Take a real-world example: Picture analyzing employee salaries (in thousands) alongside years of service (single digits). Without normalization, tenure would barely register. Post-normalization, both shine equally, revealing true retention drivers. In business, this evens out global datasets normalizing currency values across markets ensures your fraud detection model doesn’t flag international transactions unfairly.
Nuances matter: Min-max normalization shines for neural networks bounded by activation functions, but watch for sensitivity to outliers; robust scalers clip extremes. Standardization? It’s the go-to for gradient-based optimizers in deep learning, as it accelerates convergence studies show 2-5x faster training on normalized inputs.

Pro Insight and Trend Watch: With federated learning on the rise, differential privacy tweaks normalization to mask individual contributions, vital for GDPR-compliant HR analytics. Tools like scikit-learn’s StandardScaler make it seamless chain it in a Pipeline for end-to-end automation.
Transformation: Reshaping for the Win, from Skewed to Symmetric
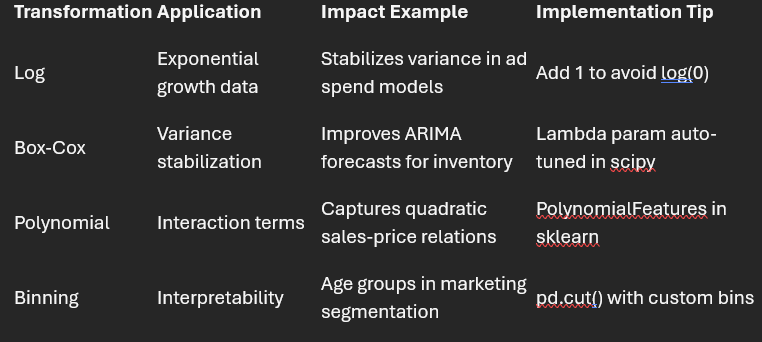
Transformation isn’t just cosmetic; it’s sculpting data to unlock hidden patterns. Log transformations tame skewed distributions (hello, income data), while binning turns continuous vars into categories for interpretability.
Common methods include:
Polynomial Features for non-linear relationships, or one-hot encoding for categoricals.
Box-Cox for stabilizing variance in time-series sales forecasts.
Transformations unlock non-linear insights log for right-skewed positives (e.g., website traffic), Yeo-Johnson for negatives too. Feature engineering via PCA reduces dimensionality post-transformation, cutting compute costs in large-scale deployments.
Anecdote Time: I once transformed a skewed e-commerce clickstream dataset with a square-root function. Suddenly, our recommendation engine went from “meh” to “spot-on,” increasing click-through rates by 18%. Case in point: Transforming geospatial data via Haversine distances for a ride-sharing app refined route optimizations, boosting efficiency by 12% amid urban sprawl. As multimodal AI grows, expect vector embeddings to transform text alongside numericals seamlessly. Ethically, document biases introduced (e.g., imputation favoring majorities) to foster trust.
Integration, Best Practices, and Tools to Tie It All Together
By weaving these techniques into your workflow perhaps using scikit-learn’s Pipeline for automation you’re not just prepping data; you’re priming your business for smarter, faster insights. Chain them as Clean → Transform → Normalize, and experiment on Kaggle datasets to internalize. Tools like KNIME or DataRobot automate this, but understanding the why keeps you agile. In 2025’s AI landscape, edge computing demands lightweight preprocessing think on-device normalization for mobile health apps.
Whether you’re a solo analyst or leading a data team, this toolkit equips you for tomorrow’s challenges. Pair it with hands-on practice, and you’ll see those model gains firsthand.
💵 50% Off All Live Bootcamps and Courses
📬 Daily Business Briefings; All edition themes are different from the other.
📘 1 Free E-book Every Week
🎓 FREE Access to All Webinars & Masterclasses
📊 Exclusive Premium Content
Recommended Reads
A Practical Guide to Clean and Transform Data for Machine Learning
This hands-on tutorial walks through real code snippets for handling messy datasets, perfect for beginners turning theory into practice.Data Preprocessing Techniques: Normalization, Standardization, and Encoding
Dive into scaling methods with clear examples and why they matter for model stability ideal if you’re troubleshooting uneven feature impacts.Mastering Data Preprocessing: Simplified Guide to Feature Scaling and Transformations
A straightforward explainer on advanced tweaks like Box-Cox, with business case studies to show ROI in analytics pipelines.
Trending in AI and Data Science
Let’s catch up on some of the latest happenings in the world of AI and Data Science
Nigeria’s $1 Billion AI Data Center Boom
Nigeria is emerging as Africa’s leading AI hub with $1 billion in investments from global tech players like Equinix and Microsoft to expand data centers powering digital and AI growth initiatives. Congo’s Hydro Power Pitch for AI Future
The Democratic Republic of Congo is promoting the Inga hydroelectric site the world’s largest potential hydro source as a green energy base for powering AI-focused data centers and global tech expansion. Poolside and CoreWeave’s Mega Data Center
AI startup Poolside is teaming up with CoreWeave to build Project Horizon, a massive 2‑gigawatt data centerin West Texas aimed at meeting the escalating compute demands of AI systems.
Trending AI Tool: Numerous.ai

As we wrap up, let’s spotlight Numerous.ai, a game-changer for automating data cleaning in spreadsheets. This AI sidekick handles imputation, deduping, and even basic transformations with natural language prompts like “normalize this column to 0-1”saving hours on prep work. It’s especially handy for business analysts juggling Excel without diving into code.
Learn more.
Follow Us:
LinkedIn | X (formerly Twitter) | Facebook | Instagram
Please like this edition and put up your thoughts in the comments.

Vibe Coding Certification - Live Online
Weekends Sessions | Ideal for Non Coders | Learn to code using AI