
Build Your First Decision Tree
Edition #169 | 30 July 2025


Join the Waitlist for enrolling at $595. Starts TODAY
Please fill this short form - https://tally.so/r/w2RM8M
Explore More details about the Program Here
Hello!
Welcome to today's edition of Business Analytics Review!
today’s edition of Business Analytics Review, your go-to source for the latest insights in Artificial Intelligence and Machine Learning. As we continue our journey into the fascinating world of AI, today’s focus is on a fundamental yet powerful concept: Building Your First Decision Tree. Whether you’re a complete beginner or looking to refresh your understanding, this guide will walk you through the essentials of decision trees, from their basic principles to practical applications, all while keeping things simple and engaging.
What is a Decision Tree?
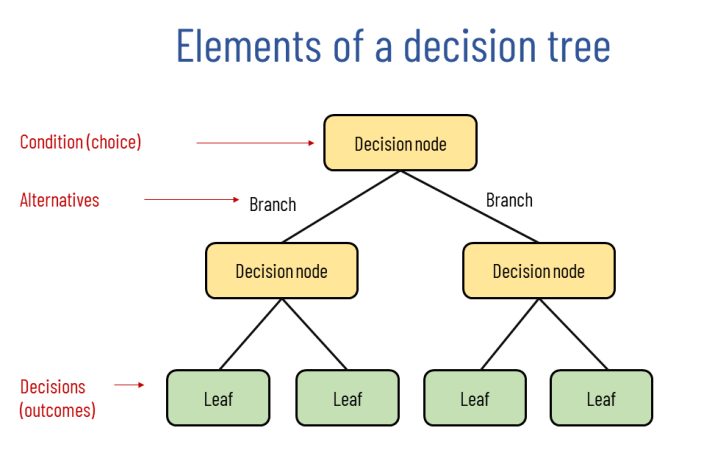
A decision tree is a supervised learning technique used for both classification (predicting categories, like whether a customer will buy a product) and regression (predicting numerical values, like a house’s price). It works by breaking down a dataset into smaller subsets while simultaneously developing a decision-making tree. Each internal node of the tree represents a "test" on a feature (e.g., "Is the age greater than 30?"), each branch represents the outcome of the test, and each leaf node represents a final decision or prediction.
Imagine you’re deciding whether to go hiking this weekend. You might ask: Is it raining? If no, is it warm enough? If yes, you go hiking; if not, you stay home. That’s exactly how a decision tree works—it asks questions about your data to make predictions, making it a natural fit for decision-making tasks.
How Do Decision Trees Work?
At the heart of a decision tree are two key concepts: splitting criteria and depth control.
Splitting Criteria: This is how the tree decides where to split the data. For regression tasks, the goal is to minimize the Residual Sum of Squares (RSS), which measures how much the predictions deviate from the actual values. For classification, common criteria include:
Gini Index: Measures the impurity of a node (how mixed the classes are). A lower Gini index means a more "pure" node, where most data points belong to the same class.
Cross-Entropy (or Deviance): Similar to the Gini Index, it’s defined is often preferred for its mathematical properties.
Hit Rate/Error: Simply counts how many predictions are correct, though it’s less commonly used as it may not optimize prediction accuracy as well as Gini or Cross-Entropy.
The algorithm chooses the split that maximizes the purity of the resulting nodes, ensuring the data is separated as clearly as possible.
Depth Control: A decision tree can grow very deep, capturing every detail in the training data, which might lead to overfitting—where the tree performs well on training data but poorly on new, unseen data. To prevent this:
Recursive Binary Splitting (RBS): The tree grows by splitting nodes into two branches at each step, choosing the best split based on the chosen criteria (e.g., minimizing RSS or Gini Index).
Pruning: After growing the tree, unnecessary branches are removed to simplify the model and improve generalization. This is often done using a tuning parameter ((alpha)) to balance tree complexity and fit, similar to regularization in other models.
Termination Criteria: The tree stops growing when it reaches a maximum depth, when there are too few samples in a node, or when the data in a node is sufficiently homogeneous (e.g., all data points belong to the same class).
Common Pitfalls
While decision trees are powerful and interpretable, they come with challenges that beginners should be aware of:
Overfitting: Deep trees can become too complex, fitting noise in the training data rather than general patterns. Pruning or limiting the maximum depth helps mitigate this.
Sensitivity to Data Changes: Small changes in the training data can lead to very different tree structures, making them less stable than other models.
Bias Toward Features with Many Levels: Decision trees may favor features with more possible values (e.g., a feature with 10 categories vs. one with 2), which can lead to biased splits if not handled carefully.
Handling Imbalanced Data: If one class dominates the dataset, the tree may struggle to predict the minority class accurately. Techniques like reweighting or oversampling can help.
To avoid these pitfalls, always validate your model on a separate test set, use pruning, and consider ensemble methods like Random Forests, which combine multiple trees to improve stability and performance.
Practical Applications
Decision trees are versatile and widely used across industries due to their interpretability and ability to handle both numerical and categorical data. Here are some real-world examples:
Finance: Banks use decision trees for credit scoring to decide whether to approve a loan, or for fraud detection by identifying suspicious transactions.
Healthcare: Hospitals apply decision trees to diagnose diseases (e.g., predicting whether a patient has diabetes based on symptoms) or assess patient risks (e.g., likelihood of readmission).
Marketing: Companies predict customer churn (e.g., will a customer cancel their subscription?) or segment customers for targeted advertising campaigns.
Operations: Manufacturers use decision trees for predictive maintenance (e.g., predicting when a machine will fail) or optimizing supply chain logistics.
Their ability to produce clear, visual decision paths makes them especially valuable in fields where decisions need to be explained to stakeholders, such as in healthcare or finance.
Recommended Reads
Beginner's Guide to Decision Trees for Supervised Machine Learning
A comprehensive introduction to decision trees, perfect for beginners, covering the basics, splitting criteria, and depth control.1.10. Decision Trees
Official documentation from scikit-learn, explaining decision trees with practical examples and code.Python Machine Learning Decision Tree
A hands-on tutorial with simple code examples for building and visualizing decision trees in Python.
Trending in AI and Data Science
Let’s catch up on some of the latest happenings in the world of AI and Data Science
Hong Kong Warns on AI Legal Liabilities
Hongkongers are cautioned about legal risks tied to AI use, as the city prepares to roll out a ChatGPT-style tool. Users must bear responsibility for compliant application.Elon Musk Announces “Baby Grok” for Kids
Elon Musk revealed that his AI startup, xAI, plans to launch “Baby Grok”—an app designed to deliver kid-friendly content. Details about features remain undisclosed.Latent Labs Launches AI for Protein Design
Latent Labs introduces LatentX, a web-based AI model allowing users to create novel proteins. The tool aims to democratize protein design for researchers and companies.
Trending AI Tool: Orange Data Mining

Orange is an open-source data visualization and machine learning toolkit designed for both beginners and experts. Its visual programming interface allows you to build data analysis workflows without writing code, making it ideal for exploring decision trees, clustering, and other ML concepts. With a wide range of widgets for data preprocessing, visualization, and modeling, Orange is perfect for hands-on learning and rapid prototyping. It’s widely used in education and research, with applications in fields like bioinformatics and geoinformatics.
Learn more.
Join the Waitlist for enrolling at $595. Starts TODAY
Please fill this short form - https://tally.so/r/w2RM8M