
Booming AI Agents
Special Edition

The most important change in AI isn’t a new model.
It’s the moment models stopped waiting for instructions — and started thinking, planning, and acting.
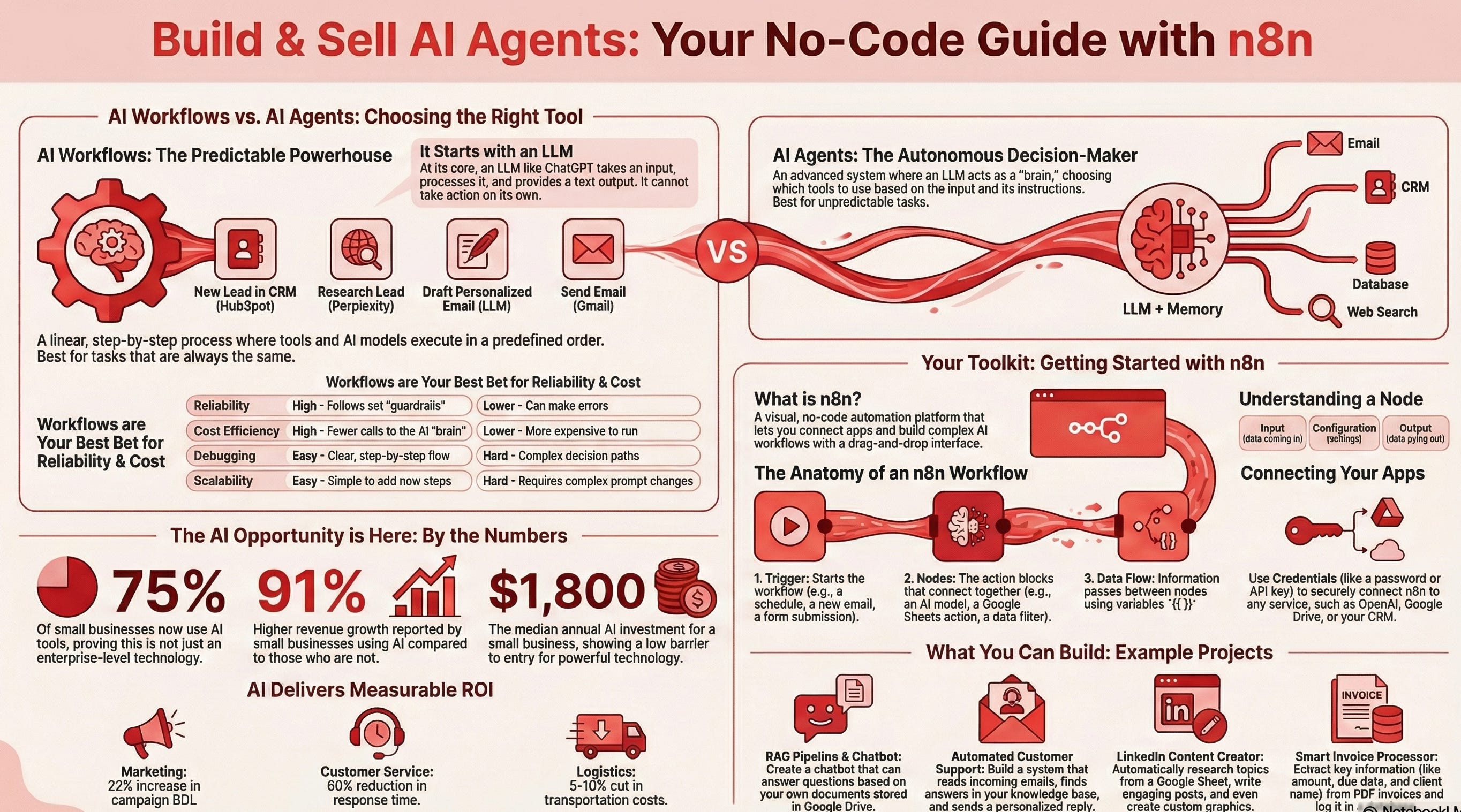
Over the past year, the AI industry has quietly crossed a threshold:
we’ve moved from single-response chatbots to reasoning systems that manage memory, coordinate tools, collaborate with other agents, and execute entire workflows on their own.
These are not demos.
They are becoming the operational backbone of modern products and teams.
This is the era of Agentic AI — and every serious AI practitioner now has to understand how these systems are actually built.
From prompts to cognition
Traditional LLMs were powerful, but brittle.
They answered questions.
Agentic systems solve problems.
They reason, plan, reflect on their own outputs, retrieve long-term memory, choose tools, monitor execution, and course-correct when something breaks — all inside structured workflows that look far more like software systems than chat conversations
What’s changing is the architecture:
Memory layers (short-term, episodic, long-term)
Retrieval pipelines and context engineering
Planning loops and self-reflection mechanisms
Multi-agent collaboration and human-in-the-loop supervision
This is the foundation that modern AI teams are now expected to build on.
Why “just knowing LangChain” isn’t enough anymore
Many engineers learned LangChain to glue LLMs to tools.
That was phase one.
Now the work is about orchestrating entire reasoning systems:
chaining retrieval, tool calls, validation, fallback logic, routing, and multi-agent coordination into dependable pipelines
That’s where context engineering, LangGraph, and agent design patterns enter — turning fragile prompts into robust, production-grade systems.
The difference is night and day.
One produces demos.
The other produces infrastructure.
The hidden power of retrieval and memory
The most underestimated part of agentic systems is memory architecture.
Modern agents don’t just “search a vector DB.”
They operate across layered memory:
session memory
episodic memory
long-term vector memory
structured knowledge stores
cached semantic results
They select context dynamically, suppress hallucinations through reasoning-driven retrieval, and continuously monitor retrieval quality and system drift
This is what allows agents to behave consistently over time — and what separates serious systems from brittle prototypes.
When agents stop working alone
As problems grow more complex, single-agent designs collapse.
Teams are now building multi-agent systems with specialized roles:
planners, retrievers, validators, tool operators, supervisors — all coordinated through routing logic, discussion loops, and hierarchical control flows
With the right architecture:
agents decompose large goals
delegate tasks in parallel
validate each other’s work
escalate uncertainty to humans
and continuously improve output quality
This is how organizations are turning LLMs into reliable digital workers.
The protocol layer most people haven’t noticed yet
Underneath this entire shift sits a new interoperability layer:
Model Context Protocol (MCP) and emerging agent communication standards.
MCP standardizes how models discover tools, data, prompts, and services — essentially acting as the “USB-C port for AI systems”
It enables agents to plug into enterprise systems, coordinate across applications, and scale without brittle custom integrations.
This protocol layer is becoming one of the most valuable skills in applied AI.
What separates experiments from production
The last mile is evaluation.
Agentic systems are only useful if they’re reliable, safe, and measurable.
That’s why modern teams are adopting multi-layer evaluation frameworks:
RAGAs, G-Eval, HELM, MMLU, reasoning benchmarks, retrieval metrics, and safety audits — not just “does it look good in the demo?”
When evaluation becomes part of the design, agents stop being risky toys and start becoming deployable systems.
The quiet conclusion
Across industries, the same pattern is emerging:
Those who understand how agents think, coordinate, retrieve, plan, and evaluate are rapidly moving from “AI user” to AI system designer.
That transition is now one of the highest-leverage career moves in this field.
And it’s happening whether we pay attention to it or not.
Further Reading & Learning Path
For readers looking to go beyond surface-level understanding of AI agents and into how these systems are actually designed and built, we’ve recently curated a structured learning experience around modern agentic systems.
It explores — in practical depth — the full lifecycle of agent development:
from reasoning models and memory architectures, to context engineering, retrieval pipelines, multi-agent coordination, protocol-driven interoperability (including MCP), and real-world evaluation frameworks.
The program is heavily lab-driven and project-focused, allowing participants to translate the concepts discussed in this edition into working, production-style agent systems.

A very Happy New Year !! Get 30% off on the AI Agents Bootcamp ..
Reply to this mail if interested !!
We’ll be sharing more technical insights from this learning track in upcoming editions of Business Analytics Review for those interested in this space.
Most of what’s being described here is really the formalization of responsibility inside AI systems. Memory layers, retrieval, evaluation, MCP — they’re not just technical components, they’re how you turn probabilistic models into accountable actors. That shift matters more than whether an agent “reasons” well.
The maturity indicators you list - layered memory, retrieval, planning loops, self-reflection - are real. These aren't hype anymore; they're implementation patterns.
MCP for enterprise integration is the piece that made custom agents practical. Before standardized protocols, every integration was custom work. Now you install an MCP server and get clean tool access.
The multi-agent coordination point is where things get interesting. My agent spawns sub-agents for parallel research. The coordination overhead is real, but so are the speed gains.
Measurable reliability (RAGAs, G-Eval, HELM) is the unsexy part that matters. You can't improve what you can't measure. Platforms that hide their evaluation make improvement harder.
I wrote about choosing to build custom rather than use platforms: https://thoughts.jock.pl/p/openclaw-good-magic-prefer-own-spells - these maturity indicators were part of the decision.