
Activation Functions in Neural Networks
Edition #135 | May 09, 2025


Master AI Agents & Build Fully Autonomous Web Interactions!
Join our AI Agents Certification Program and learn to develop AI agents that plan, reason, and automate tasks independently. A hands-on, 4-week intensive program with expert-led live sessions.
📅 Starts: 24st May | Early Bird: $1190 (Limited Spots! Price Increases to $2490 in 7 Days)
🔗 Enroll now & unlock exclusive bonuses! (Worth 500$+)
Hello!!
Welcome to the new edition of Business Analytics Review!
Today, we're diving deep into the world of activation functions, those essential mathematical operations that bring life to neural networks. Often overshadowed by other components like network architecture and loss functions, activation functions play a crucial role in determining how our neural networks learn and perform.

What Are Activation Functions?
At their core, activation functions determine whether a neuron should be "activated" or not based on its input. They introduce non-linearity into our networks, allowing them to learn complex patterns that would be impossible with linear transformations alone.
Think of activation functions as the decision-makers in our neural networks. Without them, no matter how many layers we stack, we'd essentially just have one big linear regression!
The Mathematical Landscape
Let's explore the mathematical properties of some key activation functions:
Sigmoid: The OG Activation Function
The sigmoid function squashes input values to a range between 0 and 1, following the formula:
σ(x) = 1/(1 + e^(-x))
This S-shaped curve has elegant mathematical properties—it's differentiable everywhere, which was crucial for early backpropagation algorithms. However, it suffers from the "vanishing gradient problem" for values far from zero, causing training to slow down drastically in deeper networks.
Tanh: Sigmoid's Centered Cousin
The hyperbolic tangent function is essentially a scaled sigmoid, ranging from -1 to 1:
tanh(x) = (e^x - e^(-x))/(e^x + e^(-x))
By being zero-centered, tanh addresses some issues with sigmoid but still faces vanishing gradient problems at extremes.
ReLU: The Revolution
The Rectified Linear Unit changed everything with its surprisingly simple formula:
ReLU(x) = max(0, x)
ReLU simply returns x if positive, otherwise zero. This simplicity brought computational efficiency and helped alleviate the vanishing gradient problem. However, it introduced the "dying ReLU" issue where neurons can permanently "die" during training if they consistently receive negative inputs.
Beyond the Basics
The activation function family has expanded considerably with variants like:
Leaky ReLU: Allows a small gradient when x < 0 to prevent dying neurons
ELU (Exponential Linear Unit): Combines ReLU benefits with negative values to push mean activations closer to zero
GELU (Gaussian Error Linear Unit): Increasingly popular in transformer architectures like BERT and GPT
Swish: Introduced by Google, defined as x * sigmoid(x), showing promising results in deep networks
Practical Implications
The choice of activation function significantly impacts your model's:
Training speed: Functions like ReLU compute faster than sigmoid or tanh
Convergence behavior: Different functions can lead to faster or more stable convergence
Representation capacity: Some functions better capture certain types of relationships
Output range: Important when selecting activation functions for output layers
For instance, in a typical classification model, you might use ReLU in hidden layers for efficient training, but sigmoid or softmax in the output layer to get probability-like outputs.

Our PRO newsletter is Active . Learn More Here
PRO subscribers get all our courses/bootcamp at 50 % price
You can enjoy the daily premium content at the cost of a single coffee.
Industry Insights
The evolution of activation functions mirrors the broader development of deep learning. When neural networks faced training difficulties in the early 2000s, the widespread adoption of ReLU in the 2010s played a significant role in making deeper networks practical.
Today, many state-of-the-art models use specialized activation functions for different components. For example, transformer-based language models often employ GELU activations, while some computer vision models use Swish or Mish functions for improved performance.
Recommended Readings
Activation Functions for Artificial Neural Networks
A comprehensive breakdown of current activation functions with visual representations and practical comparisonsThe Effect of Activation Functions on the Performance of Deep Neural Networks
An empirical study examining how different activation functions impact model performance across various datasets and architecturesA Gentle Introduction to the Rectified Linear Unit (ReLU)
A deep dive into why ReLU revolutionized deep learning, with interactive visualizations showing its impact on gradient flow
Trending in AI and Data Science
Let’s catch up on some of the latest happenings in the world of AI and Data Science:
OpenAI Abandons Planned For-Profit Conversion
OpenAI will transition its for-profit LLC into a Public Benefit Corporation (PBC), retaining nonprofit control and mission focusBillionaire duo launches $15bn joint venture for AI-driven deals
Billionaires launch $15bn joint venture to use artificial intelligence for identifying and executing investment deals, revolutionizing deal-making processesNvidia Wants to Use AI in the Real World, From Biotech to Transportation
Nvidia unveils AI advances for real-world use-biotech, robotics, transport-highlighting new models, industry partnerships, and deployment platforms
Tool of the Day: Activation Atlas
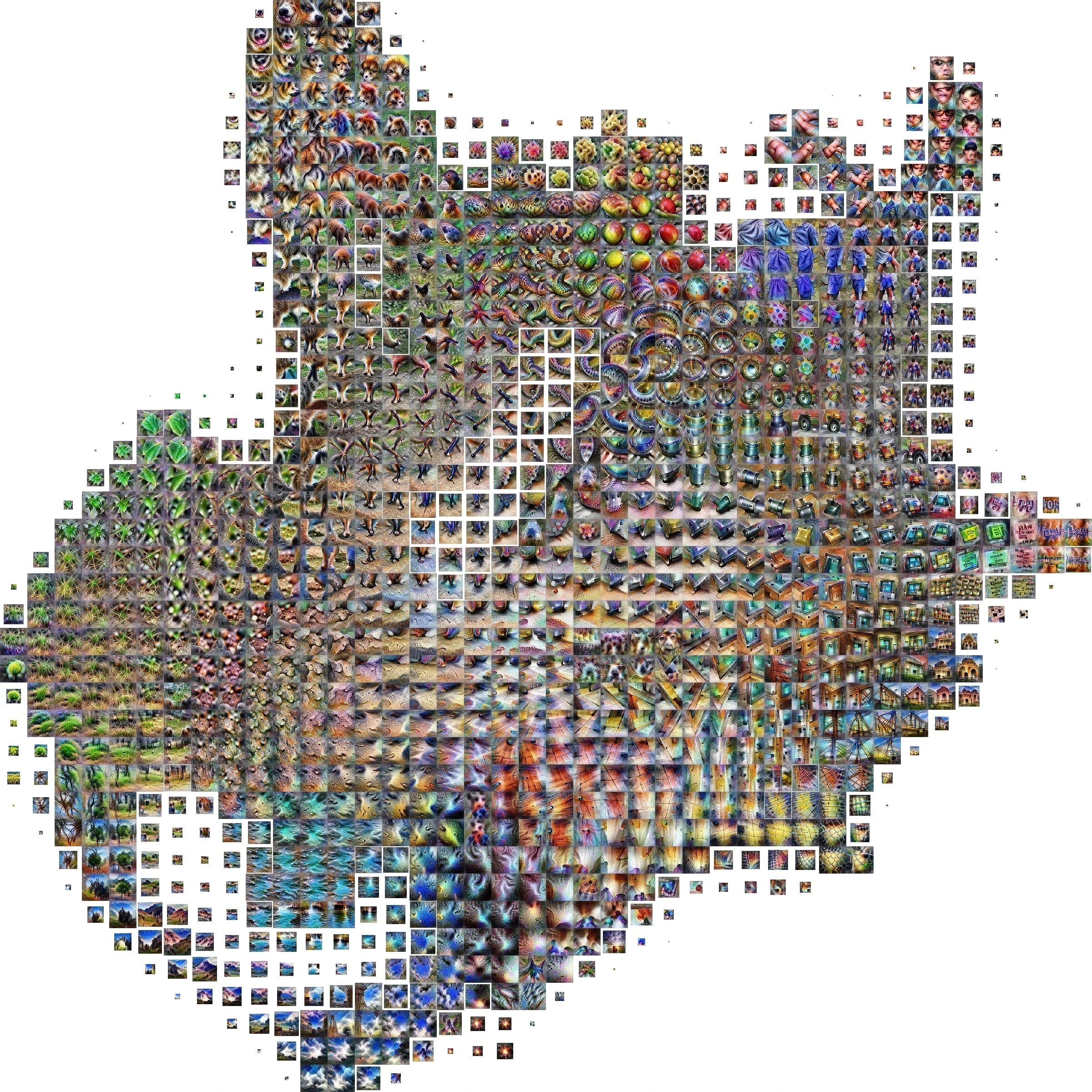
Developed by researchers at Google, Activation Atlas is a groundbreaking visualization tool that helps you understand what your neural networks are actually learning. By mapping activations of different neurons across thousands of examples, it creates a "feature atlas" that reveals how your network interprets the world. While not a traditional software tool, this open-source approach offers incredible insights into the black box of neural networks and can help you better understand how your activation functions are shaping your model's internal representations. Learn More
Thank you for joining us on this journey! Until next time, happy analyzing!
Master AI Agents & Build Fully Autonomous Web Interactions!
Join our AI Agents Certification Program and learn to develop AI agents that plan, reason, and automate tasks independently. A hands-on, 4-week intensive program with expert-led live sessions.
📅 Starts: 24st May | Early Bird: $1190 (Limited Spots! Price Increases to $2490 in 7 Days)
🔗 Enroll now & unlock exclusive bonuses! (Worth 500$+)
Merci ! Vos analyses sont très intéressantes et instructives.